Существует несколько способов получения плана выполнения, который использовать будет зависеть от ваших обстоятельств. Обычно вы можете использовать SQL Server Management Studio для получения плана, однако, если по какой-то причине вы не можете запустить свой запрос в SQL Server Management Studio, вам может оказаться полезным получить план через SQL Server Profiler или путем проверки кэш плана.
Метод 1 - Использование SQL Server Management Studio
SQL Server поставляется с несколькими опрятными функциями, которые позволяют легко выполнить план выполнения, просто убедитесь, что пункт меню «Включить фактический исполняемый план» (найденный в меню «Запрос») отмечен галочкой и запускает ваш запрос как обычно,
Если вы пытаетесь получить план выполнения для инструкций в хранимой процедуре, вы должны выполнить хранимую процедуру, например:
Exec p_Example 42
Когда ваш запрос завершен, вы увидите дополнительную вкладку «План выполнения», которая появится в панели результатов. Если вы запустили много утверждений, вы можете увидеть много планов, отображаемых на этой вкладке.
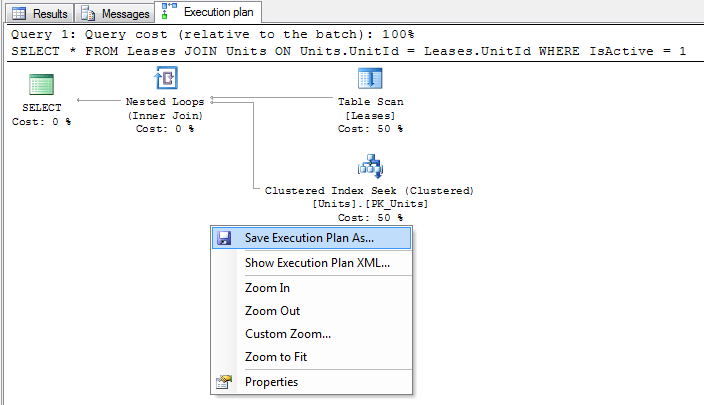
Отсюда вы можете проверить план выполнения в SQL Server Management Studio или щелкнуть правой кнопкой мыши по плану и выбрать «Сохранить план выполнения как...», чтобы сохранить план в файл в формате XML.
Способ 2 - Использование опций SHOWPLAN
Этот метод очень похож на метод 1 (на самом деле это то, что делает SQL Server Management Studio внутренне), однако я включил его для полноты или если у вас нет доступной SQL Server Management Studio.
Перед выполнением запроса запустите один следующих операторов. Оператор должен быть единственным оператором в пакете, т. Е. Вы не можете выполнять другой оператор одновременно:
SET SHOWPLAN_TEXT ON SET SHOWPLAN_ALL ON SET SHOWPLAN_XML ON SET STATISTICS PROFILE ON SET STATISTICS xml ON -- The is the recommended option to use
Это параметры подключения, поэтому вам нужно только запустить этот раз для каждого подключения. С этого момента все запущенные операторы будут сопровождаться дополнительным набором результатов , содержащим ваш план выполнения в желаемом формате, - просто запустите свой запрос, как обычно, чтобы увидеть план.
Как только вы закончите, вы можете отключить этот параметр со следующим утверждением:
SET < > OFF
Сравнение форматов плана выполнения
Если у вас нет сильных предпочтений, я рекомендую использовать параметр STATISTICS xml . Эта опция эквивалентна опции «Включить фактический план выполнения» в SQL Server Management Studio и предоставляет самую большую информацию в наиболее удобном формате.
- SHOWPLAN_TEXT - Displays a basic text based estimated execution plan, without executing the query
- SHOWPLAN_ALL - Displays a text based estimated execution plan with cost estimations, without executing the query
- SHOWPLAN_XML - Displays an xml based estimated execution plan with cost estimations, without executing the query. This is equivalent to the "Display Estimated Execution Plan..." option in SQL Server Management Studio.
- STATISTICS PROFILE - Executes the query and displays a text based actual execution plan.
- STATISTICS XML - Executes the query and displays an xml based actual execution plan. This is equivalent to the "Include Actual Execution Plan" option in SQL Server Management Studio.
Способ 3 - Использование SQL Server Profiler
Если вы не можете запустить свой запрос напрямую (или ваш запрос не выполняется медленно при его непосредственном запуске - помните, что мы хотим, чтобы план запроса выполнялся плохо), вы можете сделать план с использованием трассировки Profiler SQL Server. Идея состоит в том, чтобы запустить ваш запрос, пока трассировка, которая захватывает один из событий «Showplan», запущена.
Обратите внимание, что в зависимости от нагрузки вы можете использовать этот метод в рабочей среде, однако вы должны, очевидно, проявлять осторожность. Механизмы профилирования SQL Server предназначены для минимизации влияния на базу данных, но это не означает, что влияние производительности any не будет. У вас может также возникнуть проблема с фильтрацией и определением правильного плана в вашей трассе, если ваша база данных находится под большим использованием. Вы должны, очевидно, проверить с вашим администратором базы данных, чтобы убедиться, что они довольны тем, что вы делаете это в своей драгоценной базе данных!
- Open SQL Server Profiler and create a new trace connecting to the desired database against which you wish to record the trace.
- Under the "Events Selection" tab check "Show all events", check the "Performance" -> "Showplan XML" row and run the trace.
- While the trace is running, do whatever it is you need to do to get the slow running query to run.
- Wait for the query to complete and stop the trace.
- To save the trace right click on the plan xml in SQL Server Profiler and select "Extract event data..." to save the plan to file in xml format.
План, который вы получаете, эквивалентен опции «Включить фактический план выполнения» в SQL Server Management Studio.
Способ 4. Проверка кэша запросов.
Если вы не можете выполнить свой запрос напрямую, и вы также не можете захватить трассировку профилировщика, вы можете получить оценочный план, проверив кеш-план SQL-запросов.
Мы проверяем кеш плана, запрашивая SQL Server DMVs . Ниже приведен базовый запрос, в котором будут перечислены все кэшированные планы запросов (как xml) вместе с их текстом SQL. В большинстве баз данных вам также необходимо будет добавить дополнительные условия фильтрации, чтобы отфильтровать результаты вплоть до планов, которые вас интересуют.
SELECT UseCounts, Cacheobjtype, Objtype, TEXT, query_plan FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle) CROSS APPLY sys.dm_exec_query_plan(plan_handle)
Выполните этот запрос и щелкните на плане XML, чтобы открыть план в новом окне - щелкните правой кнопкой мыши и выберите «Сохранить план выполнения как...», чтобы сохранить план в файл в формате XML.
Заметки:
Поскольку существует так много факторов (начиная от таблицы и схемы индекса до хранящихся данных и статистики таблицы), вы должны всегда пытаться получить план выполнения из интересующей вас базы данных (обычно тот, который испытывает проблему с производительностью).
Вы не можете зафиксировать план выполнения для зашифрованных хранимых процедур.
«фактические» и «оценочные» планы выполнения
План выполнения фактический - это тот, где SQL Server фактически выполняет запрос, тогда как план выполнения оцененный SQL Server выполняет то, что он делает без выполнения запрос. Хотя логически эквивалентный, фактический план выполнения намного полезнее, поскольку он содержит дополнительные данные и статистику о том, что на самом деле произошло при выполнении запроса. Это важно при диагностике проблем, когда оценки SQL-серверов отключены (например, когда статистика устарела).
Как интерпретировать план выполнения запроса?
Это тема, достойная достаточно для бесплатного в своем собственном праве.
- SQL Server 2008 - использование хеш-запросов и хэш-планов запроса >
В дополнение к всеобъемлющему ответу, уже опубликованному иногда, полезно иметь возможность получить доступ к плану выполнения программно, чтобы извлечь информацию. Пример кода для этого ниже.
DECLARE @TraceID INT EXEC StartCapture @@SPID, @TraceID OUTPUT EXEC sp_help "sys.objects" /*<-- Call your stored proc of interest here.*/ EXEC StopCapture @TraceID
Пример StartCapture Определение
CREATE PROCEDURE StartCapture @Spid INT, @TraceID INT OUTPUT AS DECLARE @maxfilesize BIGINT = 5 DECLARE @filepath NVARCHAR(200) = N"C:\trace_" + LEFT(NEWID(),36) EXEC sp_trace_create @TraceID OUTPUT, 0, @filepath, @maxfilesize, NULL exec sp_trace_setevent @TraceID, 122, 1, 1 exec sp_trace_setevent @TraceID, 122, 22, 1 exec sp_trace_setevent @TraceID, 122, 34, 1 exec sp_trace_setevent @TraceID, 122, 51, 1 exec sp_trace_setevent @TraceID, 122, 12, 1 -- filter for spid EXEC sp_trace_setfilter @TraceID, 12, 0, 0, @Spid -- start the trace EXEC sp_trace_setstatus @TraceID, 1Пример StopCapture Определение
CREATE PROCEDURE StopCapture @TraceID INT AS WITH XMLNAMESPACES ("http://schemas.microsoft.com/sqlserver/2004/07/showplan" as sql), CTE as (SELECT CAST(TextData AS VARCHAR(MAX)) AS TextData, ObjectID, ObjectName, EventSequence, /*costs accumulate up the tree so the MAX should be the root*/ MAX(EstimatedTotalSubtreeCost) AS EstimatedTotalSubtreeCost FROM fn_trace_getinfo(@TraceID) fn CROSS APPLY fn_trace_gettable(CAST(value AS NVARCHAR(200)), 1) CROSS APPLY (SELECT CAST(TextData AS XML) AS xPlan) x CROSS APPLY (SELECT T.relop.value("@EstimatedTotalSubtreeCost", "float") AS EstimatedTotalSubtreeCost FROM xPlan.nodes("//sql:RelOp") T(relop)) ca WHERE property = 2 AND TextData IS NOT NULL AND ObjectName not in ("StopCapture", "fn_trace_getinfo") GROUP BY CAST(TextData AS VARCHAR(MAX)), ObjectID, ObjectName, EventSequence) SELECT ObjectName, SUM(EstimatedTotalSubtreeCost) AS EstimatedTotalSubtreeCost FROM CTE GROUP BY ObjectID, ObjectName -- Stop the trace EXEC sp_trace_setstatus @TraceID, 0 -- Close and delete the trace EXEC sp_trace_setstatus @TraceID, 2 GOПомимо методов, описанных в предыдущих ответах, вы также можете использовать бесплатный просмотрщик планов выполнения и инструмент оптимизации запросов План ApexSQL (с которым я недавно столкнулся).
Вы можете установить и интегрировать план ApexSQL в SQL Server Management Studio, поэтому планы выполнения можно просматривать непосредственно из SSMS.
Просмотр расчетных планов выполнения в Плане ApexSQL
- Нажмите кнопку Новый запрос в SSMS и вставьте текст запроса в текстовое окно запроса. Щелкните правой кнопкой мыши и выберите «Отображать примерный план выполнения» в контекстном меню.

- На диаграмме плана выполнения будет показана вкладка Планирование выполнения в разделе результатов. Затем щелкните правой кнопкой мыши план выполнения и в контекстном меню выберите вариант «Открыть в ApexSQL Plan».

- Предполагаемый план выполнения будет открыт в Плане ApexSQL и может быть проанализирован для оптимизации запросов.

Просмотр фактических планов выполнения в Плане ApexSQL
Чтобы просмотреть фактический план выполнения запроса, продолжайте со второго шага, упомянутого ранее, но теперь, как только появится оценочный план, нажмите кнопку «Фактический» на главной панели ленты в Плане ApexSQL.

После нажатия кнопки «Фактический» будет показан фактический план выполнения с подробным предварительным просмотром параметров затрат вместе с другими данными плана выполнения.

Более подробную информацию о просмотре планов выполнения можно найти, следуя этой ссылке .
Мой любимый инструмент для получения и глубокого анализа планов выполнения запросов - SQL Sentry Plan Explorer . Это гораздо удобнее, удобнее и полно для детального анализа и визуализации планов выполнения, чем SSMS.
Вот примерный снимок экрана, чтобы вы поняли, какая функциональность предлагается инструментом:

Это только один из видов, доступных в инструменте. Обратите внимание на набор вкладок в нижней части окна приложения, что позволяет вам получать различные типы представления плана выполнения и полезную дополнительную информацию.
Кроме того, я не заметил никаких ограничений в его бесплатной версии, которая не позволяет использовать ее ежедневно или заставляет вас покупать версию Pro в конечном итоге. Итак, если вы предпочитаете придерживаться бесплатной версии, вам ничего не запрещается.
UPDATE: (Thanks to Martin Smith ) Plan Explorer now is free! See http://www.sqlsentry.com/products/plan-explorer/sql-server-query-view for details.
Планы запросов можно получить в сеансе расширенных событий через событие query_post_execution_showplan . Вот пример сеанса XEvent:
/* Generated via "Query Detail Tracking" template. */ CREATE EVENT SESSION ON SERVER ADD EVENT sqlserver.query_post_execution_showplan(ACTION(package0.event_sequence,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack)), /* Remove any of the following events (or include additional events) as desired. */ ADD EVENT sqlserver.error_reported(ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))), ADD EVENT sqlserver.module_end(SET collect_statement=(1) ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))), ADD EVENT sqlserver.rpc_completed(ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))), ADD EVENT sqlserver.sp_statement_completed(SET collect_object_name=(1) ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))), ADD EVENT sqlserver.sql_batch_completed(ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))), ADD EVENT sqlserver.sql_statement_completed(ACTION(package0.event_sequence,sqlserver.client_app_name,sqlserver.database_id,sqlserver.plan_handle,sqlserver.query_hash,sqlserver.query_plan_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack) WHERE (.(.,(4)) AND .(.,(0)))) ADD TARGET package0.ring_buffer WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=ON,STARTUP_STATE=OFF) GO
После создания сеанса (в SSMS) перейдите в Обозреватель объектов и перейдите в раздел Управление | Расширенные события | Сессии. Щелкните правой кнопкой мыши сеанс «GetExecutionPlan» и запустите его. Щелкните его правой кнопкой мыши и выберите «Watch Live Data».
Затем откройте новое окно запроса и запустите один или несколько запросов. Вот для AdventureWorks:
USE AdventureWorks; GO SELECT p.Name AS ProductName, NonDiscountSales = (OrderQty * UnitPrice), Discounts = ((OrderQty * UnitPrice) * UnitPriceDiscount) FROM Production.Product AS p INNER JOIN Sales.SalesOrderDetail AS sod ON p.ProductID = sod.ProductID ORDER BY ProductName DESC; GO
Через минуту или два вы увидите некоторые результаты на вкладке «GetExecutionPlan: Live Data». Выберите одно из событий query_post_execution_showplan в сетке, а затем щелкните вкладку «План запроса» под сеткой. Он должен выглядеть примерно так:

EDIT : The XEvent code and the screen shot were generated from SQL/SSMS 2012 w/ SP2. If you"re using SQL 2008/R2, you might be able to tweak the script to make it run. But that version doesn"t have a GUI, so you"d have to extract the showplan XML, save it as a *.sqlplan file and open it in SSMS. That"s cumbersome. XEvents didn"t exist in SQL 2005 or earlier. So, if you"re not on SQL 2012 or later, I"d strongly suggest one of the other answers posted here.
Начиная с SQL Server 2016+, для мониторинга производительности была представлена функция Query Store. Он дает представление о выборе плана выполнения и производительности. Это не полная замена трассировки или расширенных событий, но поскольку она развивается от версии к версии, мы можем получить полностью функциональный магазин запросов в будущих выпусках SQL Server. Основной поток Query Store
- SQL Server existing components interact with query store by utilising Query Store Manager.
- Query Store Manager determines which Store should be used and
then passes execution to that store (Plan or Runtime Stats or Query
Wait Stats)
- Plan Store - Persisting the execution plan information
- Runtime Stats Store - Persisting the execution statistics information
- Query Wait Stats Store - Persisting wait statistics information.
- Plan, Runtime Stats and Wait store uses Query Store as an extension to SQL Server.

- Query Store is not active for new databases by default.
- You cannot enable the query store for the master or tempdb database.
- Available DMV
Collect Information in the Query Store : We collect all the available information from the three stores using Query Store DMV (Data Management Views).
Query Plan Store: Persisting the execution plan information and it is accountable for capturing all information that is related to query compilation.
Runtime Stats Store: Persisting the execution statistics information and it is probably the most frequently updated store. These statistics represent query execution data.
. У последнего также есть полезная бонусная функция выбора плана для конкретного оператора , а не всей партии. Вот как вы используете его для просмотра планов текущих запущенных операторов:SELECT p.query_plan FROM sys.dm_exec_requests AS r OUTER APPLY sys.dm_exec_text_query_plan(r.plan_handle, r.statement_start_offset, r.statement_end_offset) AS p
Текстовый столбец в результирующей таблице, однако, не очень удобен по сравнению с столбцом XML. Чтобы иметь возможность щелкнуть результат, который будет открыт на отдельной вкладке в виде диаграммы, без необходимости сохранять его содержимое в файл, вы можете использовать небольшой трюк (помните, что вы не можете просто использовать CAST (... AS XML)), хотя это будет работать только для одной строки:
SELECT Tag = 1, Parent = NULL, = query_plan FROM sys.dm_exec_text_query_plan(-- set these variables or copy values -- from the results of the above query @plan_handle, @statement_start_offset, @statement_end_offset) FOR xml EXPLICIT
Enabling the Query Store : Query Store works at the database level on the server.
План выполнения SQL-запроса, или план запроса, - это последовательность шагов или инструкций СУБД, необходимых для выполнения SQL-запроса. На каждом шаге операция, инициировавшая данный шаг выполнения SQL-запроса, извлекает строки данных, которые могут формировать конечный результат или использоваться для дальнейшей обработки. Инструкции плана выполнения SQL-запроса представляются в виде последовательности операций, которые ВЫПОЛНЯЮТСЯ СУБД ДЛЯ предложений SQL SELECT, INSERT, delete и update. Содержимое плана запроса, как правило, представляется древовидной структурой и включает в себя следующую информацию:
- порядок соединения источников данных (таблиц, представлений и т.п.);
- метод доступа для каждого источника данных;
- методы соединения источников данных;
- операции ограничения выбора данных, сортировки и агрегирования;
- стоимость и кардинальность каждой операции;
- возможное использование секционирования и параллелизма. Информация, предоставляемая планом выполнения SQL-запроса, позволяет разработчику увидеть, какие подходы и методы выбирает оптимизатор для выполнения SQL-операций.
Интерпретация плана выполнения SQL-запроса
Визуализация плана выполнения SQL-запроса зависит от инструментов и средств разработки, которые могут как входить в состав СУБД, запрос которой представляет интерес для анализа, так и являться отдельными коммерческими или свободно распространяемыми программными продуктами, не имеющими прямого отношения к конкретному производителю СУБД. Использование того или иного инструмента визуализации плана выполнения запроса, как правило, существенно не влияет на восприятие того, что описывает представленный план запроса. Определяющей в процессе анализа того, каким путем пойдет оптимизатор при выполнении конкретного запроса, является способность верно интерпретировать информацию, которая представлена в плане запроса.
Как уже упоминалось, план SQL-запроса имеет древовидную структуру, которая описывает не только последовательность выполнения SQL-операций, но также и связь между этими операциями. Каждый узел дерева плана запроса - это операция, например сортировка, или метод доступа к таблице. Между узлами существует взаимосвязь родитель-потомок. Отношения родитель-потомок регулируются по следующим правилам:
- родитель может иметь одного или нескольких потомков;
- потомок имеет только одного родителя;
- операция, не имеющая родительской операции, является вершиной дерева;
- в зависимости от метода визуализации плана SQL-запроса потомок располагается с некоторым отступом относительно родителя. Потомки одного родителя располагаются на одинаковом расстоянии от своего родителя.
Рассмотрим более подробно информацию, представляемую планом выполнения SQL-запроса. Приведенные примеры выполнены в среде СУБД Oracle. В качестве инструмента выполнения запросов и визуализации плана SQL-запросов был использован Oracle SQL Developer. Фрагмент плана SQL-запроса представлен на рис. 10.11.
I Id I Operation
- 0RDER_ITEMS
PR0DUCT_INF0RMATI0N_PK PRODUCT INFORMATION
SELECT STATEMENT SORT ORDER BY NESTED LOOPS NESTED LOOPS TABLE ACCESS FULL INDEX UNIQUE SCAN TABLE ACCESS BY INDEX ROWID
Рис. 10.11. Фрагмент плана выполнения SQL-запроса в среде СУБД Oracle
Используя правила отношения операций плана запроса, можно определить следующее их формальное описание.
Операция 0 - корень дерева плана запроса. Корень имеет одного потомка: операция 1.
Операция 1 - операция имеет одного потомка: операция 2.
Операция 2 - операция имеет двух потомков: операция 3 и операция 6.
Операция 3 - операция имеет двух потомков: операция 4 и операция 5.
Операция 4 - операция не имеет потомков.
Операция 5 - операция не имеет потомков.
Операция 6 - операция не имеет потомков.
Взаимодействие родитель-потомок между операциями плана запроса представлено на рис. 10.12.
Операции, выполняемые в плане запроса, можно разделить на три типа: автономные, операции не связанного объединения и операции связанного объединения (рис. 10.13).
|
Автономные |
Операции несвязанного |
Операции связанного |
||
|
операции |
объединения |
объединения |

Рис. 10.12.

Рис. 10.13.
Автономные операции - это операции, которые имеют не более одной дочерней операции.
Правила следования, по которым выполняются автономные операции, можно сформулировать следующим образом.
- 2. Каждая дочерняя операция выполняется только один раз.
- 3. Каждая дочерняя операция возвращает свой результат родительской операции.
На рис. 10.14 представлен план следующего запроса:
SELECT o.order_id ,о.order_status FROM orders о ORDER BY о.order_status
Данный запрос содержит только автономные операции.
Учитывая правила следования автономных операций, последовательность их выполнения будет следующая.
- 1. В соответствии с правилом следования автономных операций № 1 первой будет выполнена операция с ID = 2. Выполняется последовательное чтение всех строк таблицы orders.
- 2. Далее выполняется операция с ID = 1. Выполняется сортировка строк, возвращаемых операцией с ID = 2, по условию предложения сортировки ORDER BY.
- 3. Выполняется операция с ID = 0. Возвращается результирующий набор данных.
Операции несвязанного объединения
Операции несвязанного объединения - это операции, которые имеют более одной независимо выполняемой дочерней операции. Пример: HASH JOIN, MERGE JOIN, INTERSECTION, MINUS, UNION ALL.
Правила следования, по которым работают операции несвязанного объединения, можно сформулировать следующим образом.
- 1. Дочерняя операция выполняется перед родительской операцией.
- 2. Дочерние операции выполняются последовательно, начиная с наименьшего значения ID операции в порядке возрастания этих значений.
- 3. Перед началом работы каждой следующей дочерней операции текущая операция должна быть выполнена полностью.
- 4. Каждая дочерняя операция выполняется только один раз независимо от других дочерних операций.
- 5. Каждая дочерняя операция возвращает свой результат родительской операции.
На рис. 10.15 представлен план следующего запроса:
SELECT o.order_id from orders о UNION ALL
SELECT oi.order_id from order_items oi
Данный запрос содержит операцию несвязанного объединения UNION all. Остальные две операции являются автономными.
Рис. 10.15. Операции несвязанного объединения, план запроса
|
1 SELECT STATEMENT I |
|||
Учитывая правила следования операций несвязанного объединения, последовательность их выполнения будет следующей.
- 1. В соответствии с правилами 1 и 2 следования операций несвязанного объединения первой будет выполнена операция с ID = 2. Выполняется последовательное чтение всех строк таблицы orders.
- 2. В соответствии с правилом 5 операция с ID = 2 возвращает считанные на шаге 1 строки родительской операции с ID = 1.
- 3. Операция с ID = 3 начнет выполняться, только когда закончится операция с ID = 2.
- 4. После окончания выполнения операции с ID = 2 начинает выполняться операция с ID = 3. Выполняется последовательное чтение всех строк таблицы order_items.
- 5. В соответствии с правилом 5 операция с ID = 3 возвращает считанные на шаге 4 строки родительской операции с ID = 1.
- 6. Операция с ID = 1 формирует результирующий набор данных на основе данных, полученных от всех ее дочерних операций (с ID = 2 и ID = 3).
- 7. Выполняется операция с ID = 0. Возвращается результирующий набор данных.
Таким образом, можно отметить, что операция независимого объединения последовательно выполняет свои дочерние операции.
Операции связанного объединения
Операции связанного объединения - это операции, которые имеют более одной дочерней операции, причем одна из операций контролирует выполнение остальных. Пример: nested loops, update.
Правила следования, по которым работают операции связанного объединения, можно сформулировать следующим образом.
- 1. Дочерняя операция выполняется перед родительской операцией.
- 2. Дочерняя операция с наименьшим номером операции (ID) контролирует выполнение остальных дочерних операций.
- 3. Дочерние операции, имеющие общую родительскую операцию, выполняются, начиная с наименьшего значения ID операции в порядке возрастания этих значений. Остальные дочерние операции выполняются НЕ последовательно.
- 4. Только первая дочерняя операция выполняется один раз. Все остальные дочерние операции выполняются несколько раз либо не выполняются совсем.
На рис. 10.16 представлен план следующего запроса:
FROM order_items oi, orders о
WHERE o.order_id= oi.order_id
AND oi.product_id>100
AND о.customer_id between 100 and 1000
Данный запрос содержит операцию связанного объединения NESTED LOOPS.
I Id I Operation
|
SELECT STATEMENT | |
|||||
Рис. 10.16. Операции связанного объединения, план запроса
Учитывая правила следования операций связанного объединения, последовательность их выполнения будет следующей.
- 1. В соответствии с правилами 1 и 2 следования операций связанного объединения первой должна быть выполнена операция с ID = 2. Однако операции с 1D = 2 и 1D = 3 являются автономными, и в соответствии с правилом 1 следования автономных операций первой будет выполнена операция с ID = 3. Выполняется просмотр диапазона индекса ORDCUSTOMERIX по условию: о. customer id between 100 and 1000.
- 2. Операция с ID=3 возвращает родительской операции (с Ш=2) список идентификаторов строк Rowld, полученных на шаге 1.
- 3. Операция с ID = 2 выполняет чтение строк в таблице orders, в которых значение Rowld соответствует списку значений Rowld, полученных на шаге 2.
- 4. Операция с ID = 2 возвращает считанные строки родительской операции (с ID = 1).
- 5. Для каждой строки, возвращаемой операцией с ID = 2, выполняется вторая дочерняя операция (с ID = 4) операции nested loops. То есть для каждой строки, возвращаемой операцией с ID = 2, выполняется полный последовательный просмотр таблицы order_items с целью найти соответствие по атрибуту соединения.
- 6. Шаг 5 повторяется столько раз, сколько строк возвращает операция с ID = 2.
- 7. Операция с ID = 1 возвращает результаты работы родительской операции (с ID = 0).
- 8. Выполняется операция с ID = 0. Возвращается результирующий набор данных.
В зависимости от сложности анализируемого запроса план его выполнения может иметь достаточно сложную структуру, что на первый взгляд кажется затруднительным для его интерпретации. Методичное выполнение описанных выше правил и декомпозиция операций позволят достаточно эффективно проанализировать план выполнения SQL-запроса любой сложности. Рассмотрим пример запроса, который формирует список клиентов, количество купленных ими товаров и их общую стоимость:
SELECT с. cust_first_name customer_name,
COUNT(DISTINCT oi.product_id) as product_qty,
SUM(oi.quantity* oi.unit_price) as total_cost FROM oe.orders о INNER JOIN customers c ON
о.customer_id=c.customer_id
INNER JOIN oe.order_items oi ON o.order_id= oi.order_id GROUP BY c. cust_first_name
Последовательность операций плана данного запроса представлена на рис. 10.17.
SELECT STATEMENT I
SORT GROUP BY ЇГ
|
TABLE ACCESS FULL |
|||
|
INDEX RANGE SCAN |
|||
|
TABLE ACCESS BY INDEX ROWIDd |
|||
|
TABLE ACCESS FULL |
|||
Рис. 10.17. План запроса, последовательность выполнения операций
Опишем возможный подход к интерпретации плана выполнения 80Ь-запроса, представленного на рис. 10.17. Данный подход включает в себя два основных этапа: декомпозиция операций на блоки и определение порядка выполнения операций.
На первом этапе необходимо выполнить декомпозицию выполняемых операций на блоки. Для этого находим все операции объединения, т.е. операции, которые имеют более одной дочерней операции (на рис. 10.17 это операции 2, 3 и 4), и выделяем эти дочерние операции в блоки. В результате, используя пример на рис. 10.17, получаем три операции объединения и семь блоков операций.
На втором этапе определяется последовательность выполнения блоков операций. Для этого необходимо применить правила следования операций, описанные выше. Выполним ряд рассуждений по вопросу выполнения каждой операции относительно ее идентификационного номера (Ш).
Операция Ш = 0 - автономная и является родительской для операции сШ = 1.
Операция Ю = 1 тоже автономная; является родительской для операции Ш = 2 и выполняется перед операцией Ю = 0.
Операция ГО = 2 - операция несвязанного объединения и является родительской для операций Ю = 3, Ю = 8. Операция ГО = 2 выполняется перед операцией ГО = 1.
Операция ГО = 3 - операция связанного объединения, является родительской для операций ГО = 4, ГО = 7. Операция ГО = 3 выполняется перед операцией ГО = 2.
Операция ГО = 4 - операция связанного объединения, является родительской для операций ГО = 5, ГО = 6. Операция ГО = 4 выполняется перед операцией ГО = 3.
Операция ГО = 5 - автономная операция, выполняется перед операцией ГО = 4.
Операция ГО = 6 - автономная операция, выполняется перед операцией ГО = 5.
Операция ГО = 7 -автономная операция, выполняется после выполнения блока операций «С».
Операция ГО = 8 - автономная операция, выполняется после блока операций «Е».
На основе проведенных рассуждений и правил следования сформулируем последовательность выполняемых операций:
- 1. Первой выполняется автономная операция ГО = 5, см. правила следования операций связанного объединения. Выполняется последовательное чтение всей таблицы.
- 2. Результат операции ГО = 5 - считанные строки таблицы - передается операции ГО = 4.
- 3. Выполняется операция ГО = 4: для каждой строки, возвращенной операцией ГО = 5, выполняется операция ГО = 6. То есть выполняется сканирование диапазона индекса по атрибуту соединения. Получение списка идентификаторов строк Яоу1с1.
- 4. Результат операции ГО = 4 передается операции ГО = 3. То есть передается список идентификаторов строк Кош1с1.
- 5. Выполняется операция ГО = 3: для каждого значения 11оу1с1, возвращенного в результате работы блока операций «С», выполняется операция ГО = 7, т.е. выполняется чтение строк таблицы по заданному списку идентификаторов строк ИтмЫ, полученных после выполнения операции Ш = 4.
- 6. Выполняется автономная операция ГО = 8 - последовательное чтение всей таблицы.
- 7. Выполняется операция несвязанного объединения ГО = 2: выполняется соединение хэшированием результатов работы блоков операций «Е» и «Е».
- 8. Результат операции ГО = 2 передается операции ГО = 1.
- 9. Выполняется операция несвязанного объединения ГО = 1: выполняется агрегирование и сортировка данных, полученных в результате работы операции ГО = 2.
- 10. Выполняется операция ГО = 0. Возвращается результирующий набор данных.
Правила следования, сформулированные для основных типов операций, применимы для большинства планов выполнения БСГО-запроса. Однако существуют конструкции, используемые в БСГО-запросах, которые предполагают нарушение порядка выполнения операций, описанных в правилах следования. Такие ситуации могут появляться в результате использования, например, подзапросов или предикатов антисоединения. В любом случае процесс интерпретации плана выполнения БСГО-запроса не предполагает только использование ряда правил, которые обеспечат именно максимально верный анализ того, что собирается делать оптимизатор при выполнении 8СГО-запроса. Очередной БСГО-запрос - это всегда индивидуальный случай; и то, как он будет выполнен в СУБД, зависит от множества факторов, среди которых версия СУБД, версия и тип операционной системы, на которой развернут экземпляр СУБД, используемая аппаратная часть, квалификация автора 80Ь-запроса и т.д.
Всем привет! Столкнулся тут недавно я с проблемой долгого проведения документа.
Вводные данные: конфигурация «Управление производственным предприятием, редакция 1.3 (1.3.52.1)», документ «Платежное поручение входящее». Жалоба: проведение в рабочей базе длится 20-30 секунд, что интересно в копии базы этот же документ проводится 2-4 секунды. О расследованиях и причине такого поведения читайте ниже.
Итак, с помощью замера производительности , как его использовать думаю, все знают, было найдено место-виновник:

В данном случае записывался пустой набор записей по регистратору, проще говоря, происходило удаление движений перед проведением. Стоить отметить, что данная процедура вызывалась 26 раз, т.е. для каждого регистра, в который мог писать наш документ.
По данным замера производительности эта операция занимала 13 секунд, если посчитать среднее, то получается 0,5 секунды на регистр, вечность просто!
Как мы все знаем, запись мы оптимизировать не можем, но тут явно что-то не так.
Для дальнейшего анализа открываем SQL Server Profiler
и . Для анализа использовал классы событий:
- Showplan Statistics Profile
- Showplan XML Statistics Profile
- RPC Completed
- SQL:BatchCompleted .
В настройках трассировки есть фильтр по SPID :

SPID — это идентификатор процесса сервера баз данных. В случае с 1С по сути соединение между сервером 1С и СУБД, посмотреть его можно в консоли администрирования серверов 1С в колонке «Соединение с СУБД».
Отображается в том случае, если в данный момент соединение с базой данных захвачено сеансом: либо выполняется вызов СУБД, либо открыта транзакция, либо удерживается объект «МенеджерВременныхТаблиц», в котором создана хотя бы одна временная таблица.
Напишем обработку для удержания SPID, в ней будет одна процедура:

Важно, чтобы удерживаемый объект соединения, в нашем случае менеджер временных таблиц, был определен как переменная обработки. Открываем обработку, запускаем процедуру и до тех пор, пока она открыта, SPID будет зафиксирован. Открываем консоль администрирования серверов 1С:
Итак, SPID получен, вводим его значение в фильтр и получаем трассировку из рабочей базы ток по своему сеансу. При анализе трассировки была найдена операция, которая выполнялась 11 секунд:

Также в глаза бросилось количество чтений — 1872578 , но я сразу не придал этому значения и начал разбирать, что и с какой таблицей тут делается.
exec sp_executesql <= @P2) AND (T1._Fld1466RRef = @P3)) OR ((T1._Period <= @P4) AND (T1._Fld1466RRef = @P5))) OR ((T1._Period <= @P6) AND (1=0)))’,N’@P1 varbinary(16),@P2 datetime2(3),@P3 varbinary(16),@P4 datetime2(3),@P5 varbinary(16),@P6 datetime2(3)’,0x8A2F00155DBF491211E87F56DD1A416E,’4018-05-31 23:59:59′,0x00000000000000000000000000000000,’4018-05-31 23:59:59′,0x9A95A0369F30F8DB11E46684B4F0A05F,’4018-05-31 23:59:59"Как видно по запросу SQL обрабатывается таблица «AccRg1465» это таблица регистра бухгалтерии Хозрасчетный. Текстовое представление плана выполнение запроса:

Как видно по плану выполнения запросу SQL ничего страшного не происходит, обрабатывается таблица «AccRg1465 », везде используется поиск по кластерному индексу.

По графическому плану тоже ничего страшного не увидел, хотя показался мне слишком раздутым — тут есть и слияние, и два вложенных цикла непонятно зачем. Откуда же такое количество чтений и гигантское время выполнения?
Как было сказано выше, в свежей копии базы проблема не воспроизводилась, копия была снята с рабочей базы после появления в ней проблемы, поэтому было решено проанализировать ее поведение в SQL Server Profiler на том же документе.
Вот результаты:
Текст запроса в SQL:
EXEC sp_executesql N"SELECT TOP 1 0x01 FROM dbo._AccRg1465 T1 WHERE (T1._RecorderTRef = 0x0000022D AND T1._RecorderRRef = @P1) AND ((((T1._Period <= @P2) AND (T1._Fld1466RRef = @P3)) OR ((T1._Period <= @P4) AND (T1._Fld1466RRef = @P5))) OR ((T1._Period <= @P6) AND (1=0)))" , N"@P1 varbinary(16),@P2 datetime2(3),@P3 varbinary(16),@P4 datetime2(3),@P5 varbinary(16),@P6 datetime2(3)" , 0x8A2F00155DBF491211E87F56DD1A416E, "4018-05-31 23:59:59" ,00, "4018-05-31 23:59:59" , 0x9A95A0369F30F8DB11E46684B4F0A05F, "4018-05-31 23:59:59"
Графическое представление плана запроса:

Тексты запроса совпадают, планы выполнения отличаются кардинально. В чем же может быть дело? Грешил на статистику в SQl, но она одинаковая между рабочей и копией базы, а статистика хранится в базе для каждой таблицы:

Анализируем дальше, если статистика одна и та же, но планы запроса разные, значит, оптимизатор не обращается к статистике для построения плана запроса, а у него есть закэшированный план, который он и использует. Чистим процедурный кэш по нашей базе, для этого используем команду
DBCC FLUSHPROCINDB(< database_id >)
где < database_id > — это идентификатор базы. Чтобы узнать идентификатор базы нужно выполнить скрипт
select name, database_id from sys . databasesон вернет нам список баз и их идентификаторы.
Получаем опять трассировку:

Текстовое представление плана запроса:

Графическое представление плана запроса:

Как видно план запроса был заново получен оптимизатором, а не использовался старый закэшированный, время выполнение пришло в норму, как и количество чтений. Что стало причиной не ясно, возможно большое количество обменов или закрытие прошлых периодов, тяжело сказать. Регламентное обслуживание баз настроено. Впервые сталкиваюсь с обманом закэшированного плана выполнения запроса.
Спасибо за внимание!
Помогла ли вам данная статья?
Рассмотрим некоторые примеры оптимизации запросов и представление соответствующих деревьев их плана выполнения. На рисунке 27 приведен запрос и план его выполнения. В данном примере таблица Клиент 1 не имеет индекса по полю Имя. Для выбора информации по условию Имя = ‘Петров 4 используется просмотр строк таблицы (т.е. последовательно читается вся таблица без использования индекса).
Рис. 27.
На рисунке 28 приведен другой запрос к этой же таблице и план его выполнения. В этом примере таблица Клиент 1 имеет некластеризо- ванный индекс по полю Кодклиента. Для выбора информации по условию Кодклиента =2 сначала используется поиск в индексе и по найденному значению RID производится обращение к соответствующей странице данных таблицы КлиентТ Таким образом, запрос с условием для индексированного поля может использовать оптимальный план с применением индекса. Для запроса с условием для неиндексированно- го поля индекс в плане использоваться не может.

Рис. 28.
На рисунках 29, 30 приведены планы выполнения для запросов к таблице Клиент, которая имеет кластеризованный индекс. На рисунках видно, что независимо от того, по какому полю задано условие в запросе, используется Кластеризованный индекс (в разделе Организация хранения данных в MS SQL Server было показано, что кластеризованный индекс объединяет дерево индекса и данные). Отличие состоит в том, что если условие в запросе задано по индексированному полю (в данном примере поле Кодк- лиента), то используется поиск в индексном дереве (Clustered Index Seek, рисунок 30). В противном случае используется последовательное сканирование индексного дерева (Clustered Index Scan, рисунок 29).

Рис. 29.

Рис. 30.
На рисунках 31, 32 приведены планы выполнения для запросов к таблице new_addresses, которая имеет некластеризованный индекс для столбца StateProvincelD. Первый запрос по условию a.StateProvincelD = 32 является высоко селективным (выбирается одна строка из 19814):
SELECT * FROM new_addresses AS a WHERE a.StateProvincelD = 32;
В этом случае из структуры плана видно (рисунок 31), что оптимизатор использует поиск в индексе для столбца StateProvincelD с последующим побращением к странице данных таблицы по найденному R1D. Оператор Nested Loops (вложенный цикл) отображается для запроса к одной таблице (внешний цикл поиск в индексе, внутренний - обращение к таблице).

Рис. 31.
Второй запрос по условию a.StateProvincelD = 9 является низко селективным (отношение количества строк, удовлетворяющему условию, к общему количеству строк равно 23%):
SELECT * FROM new_addresses а WHERE a.StateProvincelD -9;
В этом случае из структуры плана видно (рисунок 32), что оптимизатор не использует поиск в индексе для столбца StateProvincelD, а обращается непосредственно к страницам таблицы данных (индекс не используется, таблица сканируется).

Рис. 32.
Рассмотрим пример использования подсказки оптимизатору WITH(INDEX(0)). Если не существует кластеризованный индекс для таблицы, то INDEX (0) требует сканирований таблицы. При существовании кластеризованного индекса INDEX (0) определяет сканирование кластеризованного индекса.
USE AdventureWorks;
SELECT * FROM Per son. Address AS a WHERE a.StateProvincelD = 32.
Дерево плана выполнения запроса показано на рисунке 33.

Рис. 33.
USE AdventureWorks;
SELECT * FROM Person.Address AS a W1TH(INDEX(0))
WHERE a.StateProvincelD = 32.
Дерево плана выполнения запроса показано на рисунке 34. Видно, что с этой подсказкой не используется поиск в некластеризованном индексе.

Рис. 34.
Рассмотрим примеры планов выполнения запросов с разными техниками обработки соединения таблиц. В соединяемых столбцах таблиц HumanResources.Employee и HumanResources.EmployeeAddress имеются первичные ключи и, соответственно, - кластеризованные индексы. На рисунке 35 показано, что в таблице HumanResources.EmployeeAddress имеется составной кластеризованный индекс по полям EmployeelD и AddressID.

Рис. 35.
В первом запросе задано условие e.EmployeelD = 10:
USE AdventureWorks;
SELECT * FROM HumanResources.Employee AS e JOIN HumanResources.EmployeeAddress AS a ON e.EmployeelD = a.EmployeelD AND e.EmployeelD = 10;
Дерево плана запроса показано на рисунке 36. Видно, что используется техника обработки соединения Вложенные циклы. Оптимизатор принимает решение использовать вложенные циклы, так как существует дополнительный фильтр (e.EmployeelD = 10),
сокращающий результирующий набор до одной строки. Сначала производится поиск по индексу в таблице HumanResources.Employee соответствующей условию строки. Далее поиск в таблице HumanResources.EmployeeAddress. Оператор Clustered Index Seek использует поисковые возможности индексов для получения строк из кластеризованного индекса.

Рис. 36.
В данном примере последовательно производится обращение к таблицам HumanResources.Employee и HumanRe-
sources.EmployeeAddress. В такой последовательности эти таблицы указаны и в запросе (FROM HumanResources.Employee AS е JOIN HumanResources.Employee Address AS a).
Поменяем последовательность таблиц в запросе:
USE AdventureWorks;
SELECT * FROM HumanRe sources. Employ ееAddress AS a JOIN HumanResources.Employee AS e ON e.EmployeelD = a.EmployeelD AND e.EmployeelD = 10;
Дерево плана останется неизменным. Т.е. изменение последовательности таблиц в запросе не повлияло на последовательность их обработки. Это происходит потому, что оптимизатор определяет первоначальный выбор из таблицы HumanResources.Employee наилучшим (по одной найденной строке производится одно обращение к таблице
HumanResources.EmployeeAddress по найденному значению). Если использовать другую последовательность обработки таблиц, то для каждой строки таблицы HumanResources.EmployeeAddress нужно много раз обращаться таблице HumanResources.Employee и стоимость выполнения запроса будет выше.
Если из запроса удалить условие:
USE AdventureWorks;
SELECT * FROM HumanResources.Employee AS e JOIN HumanResources.EmployeeAddress AS a ON e.EmployeelD = a.EmployeelD,
то техника обработки соединения изменится. Дерево плана выполнения запроса показано на рисунке 37.

Рис. 37.
В этом запросе отсутствует условие e.EmployeelD = 10 и результирующий набор содержит много строк, но они упорядочены по индексу. В этом случае оптимизатор выбирает метод слияния соединения. Merge Join (Слияние соединения).
Рассмотрим план выполнения запроса:
USE AdventureWorks;
SELECT *
ON a.StateProvincelD = s.StateProvincelD
Таблица Person.Address, ее ключи и индексы приведены на рисунке 38.

Рис. 38.
Таблица Person.StateProvince, ее ключи и индексы приведены на рисунке 39.

Рис. 39.
Дерево плана выполнения запроса показано на рисунке 40.

Рис. 40.
Видно (рисунки 38, 39), что таблицы, участвующие в соединении, имеют кластеризованные индексы и дерево плана использует соответственно сканирование кластеризованного идекса для каждой из таблиц. Техника обработки соединения- хеширование соединения. Это происходит потому, что записи таблицы Person.Address не отсортированы по полю StateProvincelD.
Приведем пример позказки соединения. Выше был приведен запрос:
USE AdventureWorks;
SELECT * FROM Person.Address a JOIN Person.StateProvince s
ON a.StateProvincelD = s.StateProvincelD
и план его выполнения, в котором использовалась техника обработки соединения - хеширование соединения (Hash Match).
При добавлении в запрос подсказки
USE AdventureWorks;
SELECT * FROM Person.Address a JOIN Person.StateProvince s
ON a.StateProvincelD = s.StateProvincelD
OPTION (MERGE JOIN),
техника обработки соединения меняется (дерево плана показано на рисунке 41). Используется техника обработки соединения- слиянием. На рисунке видно, что предварительно выполняется операция сортировки (Sort).
Оптимизация запросов в SQL Server 2005, статистика баз данных SQL Server 2005, CREATE STATISTICS, UPDATE STATISTICS, SET NOCOUNT ON, планы выполнения запросов, количество логических чтений (logical reads), хинты оптимизатора (optimizer hints), MAXDOP, OPTIMIZE FOR, руководства по планам выполнения (plan guides), sp_create_plan_guide
Если все остальные способы оптимизации производительности уже исчерпаны, то в распоряжении разработчиков и администраторов SQL Server остается последний резерв - оптимизация выполнения отдельных запросов. Например, если в вашей задаче совершенно необходимо ускорить создание какого-то одного специфического отчета, можно проанализировать запрос, который используется при создании этого отчета, и постараться изменить его план, если он неоптимален.
Отношение к оптимизации запросов у многих специалистов неоднозначное. С одной стороны, работа программного модуля Query Optimizer , который генерирует планы выполнения запросов, вызывает множество справедливых нареканий и в SQL Server 2000, и в SQL Server 2005. Query Optimizer часто выбирает не самые оптимальные планы выполнения запросов и в некоторых ситуациях проигрывает аналогичным модулям из Oracle и Informix . С другой стороны, ручная оптимизация запросов - процесс чрезвычайно трудоемкий. Вы можете потратить много времени на такую оптимизацию и, в конце концов, выяснить, что ничего оптимизировать не удалось: план, предложенный Query Optimizer изначально, оказался наиболее оптимальным (так бывает в большинстве случаев). Кроме того, может случиться так, что созданный вами вручную план выполнения запросов через какое-то время (после добавления новой информации в базу данных) окажется неоптимальным и будет снижать производительность при выполнении запросов.
Отметим также, что для выбора наилучших планов построения запросов Query Optimizer необходима правильная информация о статистике. Поскольку, по опыту автора, далеко не все администраторы знают, что это такое, расскажем о статистике подробнее.
Статистика - это специальная служебная информация о распределении данных в столбцах таблиц. Представим, например, что выполняется запрос, который должен вернуть всех Ивановых, проживающих в городе Санкт-Петербурге. Предположим, что у 90% записей в этой таблице одно и то же значение в столбце Город - "Санкт-Петербург" . Конечно, с точки зрения выполнения запроса вначале выгоднее выбрать в таблице всех Ивановых (их явно будет не 90%), а затем уже проверять значение столбца Город для каждой отобранной записи. Однако для того, чтобы узнать, как распределяются значения в столбце, нужно вначале выполнить запрос. Поэтому SQL Server самостоятельно инициирует выполнение таких запросов, а потом сохраняет информацию о распределении данных (которая и называется статистикой) в служебных таблицах базы данных.
Для баз данных SQL Server 2005 по умолчанию устанавливаются параметры AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS . При этом статистика для столбцов баз данных будет создаваться и обновляться автоматически. Для самых больших и важных баз данных может получиться так, что операции по созданию и обновлению статистики могут мешать текущей работе пользователей. Поэтому для таких баз данных иногда эти параметры отключают, а операции по созданию и обновлению статистики выполняют вручную в ночное время. Для этого используются команды CREATE STATISTICS и UPDATE STATISTICS .
Теперь поговорим об оптимизации запросов.
Первое, что необходимо сделать, - найти те запросы, которые в первую очередь подлежат оптимизации. Проще всего это сделать при помощи профилировщика, установив фильтр на время выполнения запроса (фильтр Duration в окне Edit Filter (Редактировать фильтр), которое можно открыть при помощи кнопки Column Filters на вкладке Events Selection окна свойств сеанса трассировки). Например, в число кандидатов на оптимизацию могут попасть запросы, время выполнения которых составило более 5секунд. Кроме того, можно использовать информацию о запросах, которая предоставляется Database Tuning Advisor .
Затем нужно проверить, устанавлен ли для ваших соединений, хранимых процедур и функций параметр NOCOUNT . Установить его можно при помощи команды SET NOCOUNT ON . При установке этого параметра, во-первых, отключается возврат с сервера и вывод информации о количестве строк в результатах запроса (т. е. не отображается строка "N row(s) affected" на вкладке Messages (C ообщения) окна работы с кодом при выполнении запроса в Management Studio ). Во-вторых, отключается передача специального серверного сообщения DONE_IN_PROC , которое по умолчанию возвращается для каждого этапа хранимой процедуры. При вызове большинства хранимых процедур нужен только результат их выполнения, а количество обработанных строк для каждого этапа никого не интересует. Поэтому установка параметра NOCOUNT для хранимых процедур может серьезно повысить их производительность. Повышается скорость выполнения и обычных запросов, но в меньшей степени (до 10%).
После этого можно приступать к работе с планами выполнения запросов.
План выполнения запроса проще всего просмотреть из SQL Server Management Studio . Для того чтобы получить информацию об ожидаемом плане выполнения запроса, можно в меню Query (Запрос) выбрать команду Display Estimated Execution Plan (Отобразить ожидаемый план выполнения). Если вы хотите узнать реальный план выполнения запроса, можно перед его выполнением установить в том же меню параметр Include Actual Execution Plan (Включить реальный план выполнения). В этом случае после выполнения запроса в окне результатов в SQL Server Management Studio появится еще одна вкладка Execution Plan (План выполнения), на которой будет представлен реальный план выполнения запроса. При наведении указателя мыши на любой из этапов можно получить о нем дополнительную информацию (рис. 11.15).
Рис. 11.15. План выполнения запроса в SQL Server Management Studio
В плане выполнения запроса, как видно на рисунке, может быть множество элементов. Разобраться в них, а также предложить другой план выполнения - задача достаточно сложная. Надо сказать, что каждый из возможных элементов оптимален в своей ситуации. Поэтому обычно этапы оптимизации запроса выглядят так:
q вначале в окне Management Studio выполните команду SET STATISTICS IO ON . В результате после каждого выполнения запроса будет выводиться дополнительная информация. В ней нас интересует значение только одного параметра - Logical Reads . Этот параметр означает количество логических чтений при выполнении запросов, т. е. сколько операций чтения пришлось провести при выполнении данного запроса без учета влияния кэша (количество чтений и из кэша, и с диска). Это наиболее важный параметр. Количество физических чтений (чтений только с диска) - информация не очень представительная, поскольку зависит от того, были ли перед этим обращения к данным таблицам или нет. Статистика по времени также является величиной переменной и зависит от других операций, которые выполняет в это время сервер. А вот количество логических чтений - наиболее объективный показатель, на который в наименьшей степени влияют дополнительные факторы;
q затем пытайтесь изменить план выполнения запроса и узнать суммарное количество логических чтений для каждого плана. Обычно план выполнения запроса изменяется при помощи хинтов (подсказок) оптимизатора. Они явно указывают оптимизатору, какой план выполнения следует использовать.
Хинтов оптимизатора в SQL Server 2005 предусмотрено много. Прочитать информацию о них можно в Books Online (в списке на вкладке Index (Индекс) нужно выбрать Query Hints [ SQL Server ] (Хинты запросов ), Join Hints (Хинты джойнов) или Table Hints [ SQL Server ] (Табличные хинты )). Чаще всего используются следующие хинты:
q NOLOCK , ROWLOCK , PAGLOCK , TABLOCK , HOLDLOCK , READCOMMITTEDLOCK , UPDLOCK , XLOCK - эти хинты используются для управления блокировками (см. разд. 11.5.7) ;
q FAST количество_строк - будет выбран такой план выполнения запроса, при котором максимально быстро будет выведено указанное количество строк (первых с начала набора записей). Если пользователю нужны именно первые записи (например, последние заказы), то для их максимально быстрой загрузки в окно приложения можно использовать этот хинт;
q FORCE ORDER - объединение таблиц при выполнении запроса будет выполнено точно в том порядке, в котором эти таблицы перечислены в запросе;
q MAXDOP (от Maximum Degree of Parallelism - максимальная степень распараллеливания запроса) - при помощи этого хинта указывается максимальное количество процессоров, которые можно будет использовать для выполнения запроса. Обычно этот хинт используется в двух ситуациях:
· когда из-за переключения между процессорами (context switching ) скорость выполнения запроса сильно снижается. Такое поведение было характерно для SQL Server 2000 на многопроцессорных системах;
· когда вы хотите, чтобы какой-то тяжелый запрос оказал минимальное влияние на текущую работу пользователей;
q OPTIMIZE FOR - этот хинт позволяет указать, что запрос оптимизируется под конкретное значение передаваемого ему параметра (например, под значение фильтра для WHERE );
q USE PLAN - это самая мощная возможность. При помощи такого хинта можно явно определить план выполнения запроса, передав план в виде строкового значения в формате XML . Хинт USE PLAN появился только в SQL Server 2005 (в предыдущих версиях была возможность явно определять планы выполнения запросов, но для этого использовались другие средства). План в формате XML можно написать вручную, а можно сгенерировать автоматически (например, щелкнув правой кнопкой мыши по графическому экрану с планом выполнения, представленному на рис. 11.15, и выбрав в контекстном меню команду Save Execution Plan As (Сохранить план выполнения как)).
В SQL Server 2005 появилась новая важная возможность, которая позволяет вручную менять план выполнения запроса без необходимости вмешиваться в текст запроса. Очень часто бывает так, что код запроса нельзя изменить: он жестко "прошит" в коде откомпилированного приложения. Чтобы справиться с этой проблемой, в SQL Server 2005 появилась хранимая процедура sp_create_plan_guide . Она позволяет создавать так называемые руководства по планам выполнения (plan guides ), которые будут автоматически применяться к соответствующим запросам.
Если вы анализируете запросы, которые направляет к базе данных какое-то приложение, то имеет смысл в первую очередь обратить внимание на следующие моменты:
q насколько часто в планах выполнения запроса встречается операция Table Scan (Полное сканирование таблицы). Вполне может оказаться, что обращение к таблице при помощи индексов будет эффективнее;
q используются ли в коде курсоры. Курсоры - очень простое средство с точки зрения синтаксиса программы, но чрезвычайно неэффективное с точки зрения производительности. Очень часто можно избежать применения курсоров, используя другие синтаксические конструкции, и получить большой выигрыш в скорости работы;
q используются ли в коде временные таблицы или тип данных Table . Создание временных таблиц и работа с ними требуют большого расхода ресурсов, поэтому по возможности нужно их избегать;
q кроме создания временных таблиц, значительного расхода системных ресурсов требует и изменение их структуры. Поэтому команды на изменение структуры временных таблиц должны сразу привлекать ваше внимание. Обычно есть возможность сразу создать временную таблицу со всеми необходимыми столбцами;
q иногда запросы возвращают больше данных, чем реально требуется приложению (лишнее количество столбцов или строк). Конечно, это не способствует повышению производительности;
q если приложение передает на сервер команды EXECUTE , то имеет смысл подумать о том, чтобы заменить их на вызов хранимой процедуры sp_executesql . Она обладает преимуществами в производительности по сравнению с обычной командой EXECUTE ;
q повышения производительности иногда можно добиться, устранив необходимость повторной компиляции хранимых процедур и построения новых планов выполнения запросов. Нужно обратить внимание на применение параметров, постараться не смешивать в коде хранимой процедуры команды DML и DDL и следить за тем, чтобы параметры подключения SET ANSI_DEFAULTS , SET ANSI_NULLS , SET ANSI_PADDING , SET ANSI_WARNINGS и SET CONCAT_NULL_YIELDS_NULL не изменялись между запросами (любое изменение таких параметров приводит к тому, что старые планы выполнения считаются недействительными). Обычно проблема может возникнуть тогда, когда эти параметры устанавливаются на уровне отдельного запроса или в коде хранимой процедуры.
Отметим, что в любом случае создание планов выполнения запросов вручную и использование хинтов - это крайнее средство, которого следует по возможности избегать.