Системное администрирование Linux-систем, да и вообще администрирование любой UNIX-подобной системы. Неразрывно связано с работой в командных оболочках. Для опытных системных администраторов такой способ взаимодействия с системой является гораздо более удобным и быстрым, нежели использование графических оболочек и интерфейсов. Конечно, это многим сразу покажется преувеличением, но это неоспоримый факт. Постоянно подтверждаемый на практике. А возможна такая ситуация благодаря некоторым хитростям и инструментам, используемых при работе с командной консолью. И одним из таких инструментов является использование информационных каналов и перенаправления потоков данных для процессов.
Немного теории
Следует начать с того, что для каждого процесса система предоставляет в «пользование» как минимум три информационных канала:
- STDIN – стандартный ввод;
- STDOUT – стандартный вывод;
- STDERR – стандартная ошибка.
Строгой принадлежности этих каналов для каждого процесса нет. Сами процессы изначально появившись в системе «не знают» о том, кому и как принадлежат каналы. Они (каналы) являются общесистемным ресурсом. Хотя и устанавливаются ядром от имени процесса. Каналы могут связывать файлы, каналы, связывающие другие процессы, подключения к сети и т. д.
В UNIX-подобных системах, согласно модели ввода-вывода. Каждому из информационных каналов присваивается целочисленное значение в качестве номера. Однако для безопасного доступа. к вышеприведённым каналам. За ними зарезервированы постоянные номера - 0, 1 и 2 для STDIN, STDOUT и STDERR соответственно. Во время выполнения процессов считывание входных данных происходит по STDIN. Через клавиатуру, с вывода другого процесса, файла и т. д.. А выходные данные (через STDOUT), а также данные об ошибках (через STDERR). Выводятся на экран, в файл, на вход (уже через STDIN другого процесса) в другую программу.
Для изменения направления информационных каналов и связи их с файлами существуют специальные инструкции в виде символов <, > и >>. Так, например инструкцией < можно заставить направить процессу по STDIN содержимое файла. А с помощью инструкции > процесс по STDOUT передаёт выходные данные в файл, при этом заменяется всё содержимое существующего файла целиком. При отсутствии он будет создан. Инструкция >> выполняет то же самое, что и >, но не перезаписывает файл, а дописывает вывод в его конец. Для объединения потоков (т. е. для направления их в один и тот же приёмник) STDOUT и STDERR нужно использовать конструкцию >&. Для направления одного из потоков, например STDERR в отдельное место существует инструкция 2>.
Для связывания между собой двух каналов. Например когда нужно вывод одной команды направить на вход другой. Следует использовать для этого инструкцию (символ) «|». Который означает логическую операцию «или». Однако в контексте связывания потоков данная интерпретация не имеет значения, что нередко сбивает с толку новичков. Благодаря таким возможностям можно составлять целые командные конвейеры. Что делает работу в командных оболочках очень эффективной.
Вывод в файл
Направление вывода команды и запись этого вывода в файл /tmp/somemessage:
$ echo “This is a test message” > /tmp/somemessage
В данном случае в качестве команды с выхода которой (по STDOUT) перенаправляются данные в виде текста «This is a test massage » является утилита echo. В результате создасться файл /tmp/somemessage, в котором будет запись «This is a test message». Если файл не был создан то он создасться, если создан, то все данные в нем перезапишутся. Если нужно дописать вывод в конец файла, нужно использовать оператор «>>»
$ echo “This is a test message” >> /tmp/somemessage $ cat /tmp/somemessage This is a test message This is a test message
Как видим из примера вторая команда дописала строчку в конец файла.
Получение данных из файла
Следующий пример демонстрирует перенаправление входа:
$ mail -s "Mail test" john < /tmp/somemessage
В правой части команды (после символа <) находится файл-источник /tmp/somemesage, содержимое которого перенаправляется в утилиту mail (через STDIN), которая в свою очередь, имеет в качестве собственных параметров заголовок письма и адресата (john).
Другие примеры
Следующий пример показывает, почему иногда очень полезно разделять потоки из каналов STDIN и STDERR:
$ find / -name core 2> /dev/null
Дело в том, что команда find / -name core будет «сыпать» сообщениями об ошибках, направляя их по-умолчанию в то же место, что и результаты поиска. Т. е. в терминал командной консоли, что существенно затруднит восприятие информации пользователем. Т. к. искомые результаты затеряются среди многочисленных сообщений об ошибках, связанных с режимом доступа. Конструкция 2>/dev/null заставляет утилиту find отправлять сообщения об ошибках (следующие по каналу STDERR с зарезервированным номером 2) на фиктивное устройство /dev/null, оставляя в выводе только результаты поиска.
$ find / -name core > /tmp/corefiles 2> /dev/null
Здесь конструкция > /tmp/corefiles перенаправляет вывод утилиты find (по каналу STDOUT) в файл /tmp/corefiles. Сообщения об ошибках отсеиваются на /dev/null, не попадая в вывод терминала командной консоли.
Для связывания между собой разных каналов для разных команд:
$ fsck --help | drep M
M не проверять примонтированные файловые системы
Эта команда выведет строку (или строки), содержащие символ «M» из страницы быстрой справки к утилите . Это очень удобно, когда нужно посмотреть только интересующую информацию. В данном случае утилита grep получает вывод (по инструкции |) от команды fsck —help. И далее по шаблону «M» отбрасывает всё лишнее.
Если нужно, чтобы следующая в конвейере команда выполнялась только после полного и успешного завершения предыдущей команды, то для этого следует использовать инструкцию &&, например:
$ lpr /tmp/t2 && rm /tmp/page1
Эта команда удалит файл /tmp/page1 только тогда, когда содержимое из него будет отправлено из очереди на печать. Для достижения обратного эффекта, т. е. когда нужно выполнение следующей команды в конвейере только после того, как предыдущая не выполнится (завершится с ошибкой с ненулевым кодом), то следует использовать конструкцию ||.
Когда строка кода, включающая слишком длинный конвейер команд тяжело воспринимается, можно разбивать её на логические компоненты по строкам с помощью символа обратной черты «\»:
$ ср --preserve --recursive /etc/* /spare/backup \ || echo "Make backup error"
Отдельные команды, которые должны выполняться друг за другом можно объединять в одну строку, разделяя их символом двоеточия «;»:
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter .
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
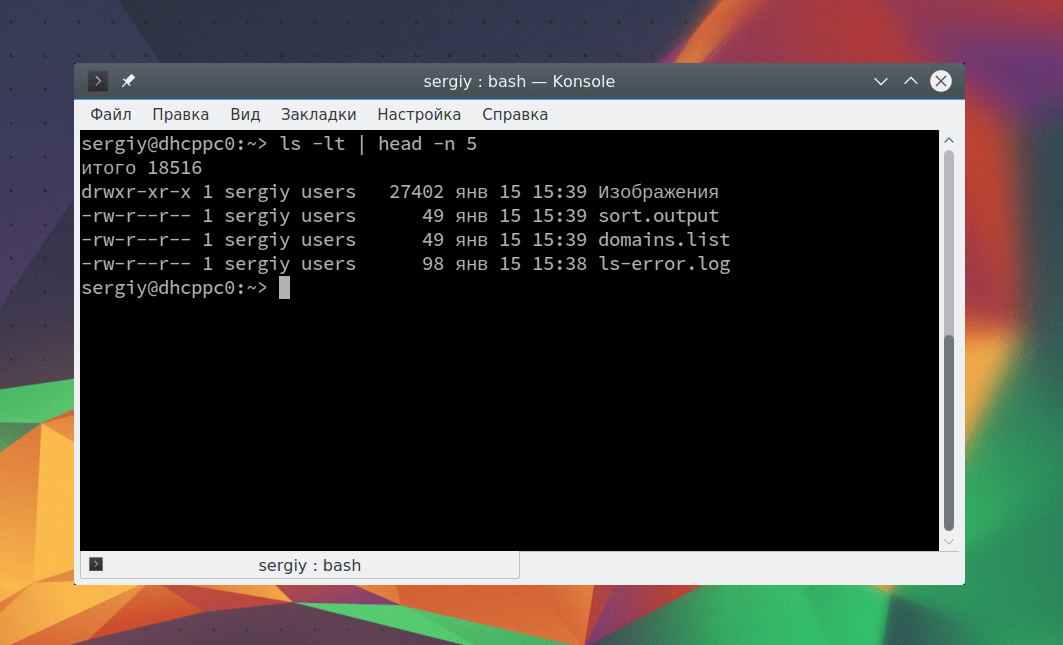
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки: Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают. Многие команды bash принимают ввод из STDIN , если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat . Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN . После того, как вы вводите очередную строку, cat просто выводит её на экран. Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды: Pwd >> myfile
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile , задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке. Ls –l xfile > myfile
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост - воспользоваться третьим стандартным дескриптором. Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран. Ls -l xfile 2>myfile
cat ./myfile
Ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT , в файл correctcontent благодаря конструкции 1> . Сообщения об ошибках, которые попали бы в STDERR , оказываются в файле errorcontent из-за команды перенаправления 2> . Если надо, и STDERR , и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &> : После выполнения команды то, что предназначено для STDERR и STDOUT , оказывается в файле content . #!/bin/bash
echo "This is an error" >&2
echo "This is normal output"
Запустим скрипт так, чтобы вывод STDERR попадал в файл. ./myscript 2> myfile
#!/bin/bash
exec 1>outfile
echo "This is a test of redirecting all output"
echo "from a shell script to another file."
echo "without having to redirect every line"
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo , попало в этот файл. Команду exec можно использовать не только в начале скрипта, но и в других местах: #!/bin/bash
exec 2>myerror
echo "This is the start of the script"
echo "now redirecting all output to another location"
exec 1>myfile
echo "This should go to the myfile file"
echo "and this should go to the myerror file" >&2
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror . Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT , в файл myfile , и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo , что приводит к записи соответствующей строки в файл myerror. Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода. Exec 0< myfile
#!/bin/bash
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(($count + 1))
done
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read , при попытке прочитать данные из STDIN , будет читать их из файла, а не с клавиатуры. Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов. Назначить дескриптор для вывода данных можно, используя команду exec: #!/bin/bash
exec 3>myfile
echo "This should display on the screen"
echo "and this should be stored in the file" >&3
echo "And this should be back on the screen"
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно: #!/bin/bash
exec 6<&0
exec 0< myfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(($count + 1))
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
y) echo "Goodbye";;
n) echo "Sorry, this is the end.";;
esac
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN . Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN , то есть из файла. После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6 . Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено. #!/bin/bash
exec 3> myfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won"t work" >&3
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору. Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом - открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно. У этой команды есть множество ключей, рассмотрим самые важные. Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей: Lsof -a -p $$ -d 0,1,2
Тип файлов, связанных с STDIN , STDOUT и STDERR - CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи. Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы: #!/bin/bash
exec 3> myfile1
exec 6> myfile2
exec 7< myfile3
lsof -a -p $$ -d 0,1,2,3,6,7
Скрипт открыл два дескриптора для вывода (3 и 6) и один - для ввода (7). Тут же показаны и пути к файлам, использованных для настройки дескрипторов. Вот, например, как подавить вывод сообщений об ошибках: Ls -al badfile anotherfile 2> /dev/null
Cat /dev/null > myfile
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах. Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так - передаём слово вам. Система ввода/вывода в LINUX
.
В системе
ввода/вывода все внешние устройства рассматриваются как файлы, над которыми
допускается производить обычные файловые операции. Конечно, существуют и
драйверы устройств, но интерфейс с ними оформлен для пользователя как обращение
к специальному файлу. Специальные файлы являются средством унификации системы
ввода/вывода.
Каждому
подключенному устройству (терминалу, дискам, принтеру и т. д.), соответствует,
как минимум, один специальный файл. Большая часть этих специальных файлов
хранится в каталоге /dev: Когда
программа выполняет запись в такой специальный файл, то ОС система
перехватывает их и направляет на устройство, например принтер). При чтении
данных из такого типа файла в действительности они принимаются с устройства,
например, с диска. Программа не должна учитывать особенности работы устройства
ввода/вывода. Для этой цели и служат специальные файлы (драйверы), которые
выполняют функции интерфейса между компонентами ядра ОС и прикладными
программами общего назначения. Система
обнаруживает отличие обычного файла от специального только после того, как
будет проанализирован соответствующий индексный дескриптор, на который
ссылается запись в каталоге. Тип и номер
устройства, также являются основными характеристиками специальных файлов (в
поле длины помещаются главный и дополнительный номера соответствующего устройства).
Первый из них определяет тип устройства, второй - идентифицирует его среди
однотипных устройств. ОС может одновременно обслуживать несколько десятков, и
даже сотни терминалов. Каждый из них должен иметь свой собственный специальный
файл, поэтому наличие главного и дополнительного номеров позволяет установить
требуемое соответствие между устройством и таким файлом. На одном диске
можно создать несколько файловых систем. Некоторые системы используют по одной
файловой системе на диске, а другие - по несколько. Новую файловую систему
можно создать с помощью команды mkfs (make file system). Например, выражение #
/sbin/mkfs /dev/dsk/fl1 512 означает: создать на флоппи-диске b: размером в 512
блоков. По желанию
можно задать размер файловой системы в блоках и количество i-узлов (т. е.
максимальное число файлов, которые могут быть сохранены в файловой системе). По
умолчанию число i-узлов равно числу блоков, деленному на четыре. Максимальное
число i-узлов в одной файловой системе 65 000. Если по некоторым причинам вам
необходимо более 65000 i-узлов на диске, необходимо создать две или более
файловые системы на этом диске. Всякая
файловая система может быть прикреплена (монтирована) к общему дереву
каталогов, в любой его точке. Например, каталог / - это корневой (root) каталог
системы, кроме этого, он является основанием файловой системы, которая всегда
монтирована. Каталог /usr1 находится в каталоге /, но в данном случае является
отдельной файловой системой от корневой файловой системы, так как все файлы в нем
находятся на отдельной части диска или вообще на отдельном диске. Файловая
система /usr1 - монтируемая файловая система - корень в точке, где каталог
/usr1 существует в общей иерархии (рис. 1 и 2). Рис. 1. Файловая система перед Рис. 2. Файловая система после Для
монтирования файловой системы используется команда /sbin/mount. Эта команда
разрешает расположить данную файловую систему везде в существующей структуре
каталогов: Если нужно
монтировать файловую систему на диски, которые должны быть защищены от записи,
чтобы система была доступна только для чтения, необходимо добавить опцию - r к
команде /sbin/mount. Чтобы получить
информацию о файловых системах, которые смонтированы, например, на системе
LINUX, можно использовать команду /sbin/mount без аргументов (рис. 3). Рис. 3.
Эта команда
выводит каталог, на который была смонтирована файловая система (например,
usrl), устройство /dev, на котором она находится, час и дата, когда она была
смонтирована. Для демонтирования файловой системы используется команда
/sbin/umount, которая имеет обратное действие по отношению к команде mount. Она
освобождает файловую систему и как бы вынимает ее целиком из структуры
каталогов, так что все ее собственные файлы и каталоги становятся недоступны: Корневая файловая
система не может быть демонтирована. Кроме того, команда umount не будет
выполнена, если кто-нибудь использует файл из той файловой системы, которую
пытаются демонтировать (это может быть даже простое пребывание пользователя в
одном из каталогов демонтируемой файловой системы).
В командах
mount и umount пользователь использует аббревиатуру физических дисковых
устройств. Для физических
устройств в LINUX существуют директории dsk и rdsk, которые содержат файлы,
соответствующие дисковым устройствам. Обыкновенно имена файлов в этих
директориях одинаковы и единственная разница между ними, что директория rdsk
содержит дисковые устройства со специальным доступом (raw), который используют
некоторые устройства системы для более быстрого доступа к диску. Одна типичная
директория dsk содержит следующие устройства: B системе
LINUX дисковые устройства логически разделены на секции, подобно разделам
определяемым в Partition Table MasterBoot MS DOS. Файлы 0s1, 0s2, 0s3 и т. д,
соответствуют секциям первой, второй, третьей и т. д. диска с номером 0. Файлы
1s0, 1sl, 1s2 и т. д. соответствуют секциям первой, второй, третьей и т. д.
диска с номером 1. Если система имеет больше дисков, секции будут пронумерованы
ns0, nsl и т. д. для каждого диска с номером n. Системы с
большим количеством дисковых устройств используют следующую систему нумерации: где controller
- номер контроллера диска; disk - номер диска; section -номер секции диска. Файлы, имена
которых начинаются с f, определяют различные виды гибких дисков. Каталог rmt
содержит файлы на устройствах типа магнитная лента: Файлы c0s0,
cls0, c2s0 и c3s0 определяют четыре кассетных ленточных запоминающих
устройства. Файлы tape и tapel определяют магнитные запоминающие устройства с
двумя бобинами. Файлы, чьи имена начинаются с n, относятся к тем же
устройствам, только лента не перематывается после использования, в то время как
использование других файлов заставляет ленту перематываться, когда использующая
ее программа заканчивает работу. В некоторых
системах эти файлы имеют другие названия, однако все они всегда находятся в /dev
и словарь, который обычно приходит с системой, содержит подробное описание
устройств и связанных с ними файлов. Файловая
система extX при операциях ввода/вывода использует буферизацию данных. При
считывании блока информации ядро выдает запрос операции ввода/вывода на
несколько расположенных рядом блоков. Такие операции сильно ускоряют извлечение
данных при последовательном считывании файлов. При занесении данных в файл
файловая система extX, записывая новый блок, заранее размещает рядом до 8
смежных блоков. Такой метод позволяет размещать файлы в смежных блоках, что
ускоряет их чтение и дает возможность достичь высокой производительности
системы. Если вывод в (графическую) консоль не очень объёмный, можно просто выдельть мышкой кусок и вставить его в сообщение щелчком средней кнопки. В противном случае можно использовать перенаправление вывода в файл через "воронку", например так: Some_command parameters > logfile.txt
Чтобы видеть результат выполнения на экране, и одновременно писать в файл, можно воспользоваться командой tee
: Some_command parameters | tee -a logfile.txt
Команда setterm -dump
создает "слепок" буфера текущей виртуальной консоли в виде простого текстового файла с именем по умолчанию - screen.dump. В качестве ее аргумента можно использовать номер консоли, для которой требуется сделать дамп. А добавление опции -file имя_файла
перенаправит этот дамп в файл с указанным именем. Опция же -append
присоединит новый дамп к уже существующему файлу - "умолчальному" screen.dump или поименованному опцией -file
. Т.е. после использования команды, например Setterm -dump -file /root/screenlog
соответственно в файле /root/screenlog
будет содержимое одной страницы консоли. Нашёл еще одно решение для копирования/вставки текста в текстовой консоли без мыши. Также можно копировать текст из буфера прокрутки (т.е. всё что на экране и выше за экраном). Чтобы лучше разобраться, читайте о консольном менеджере окон screen
. Также может пригодиться увеличить размер буфера прокрутки. 1) Запускаем screen
2) Нажимаем Enter. Всё. Мы находимся в нулевом окне консоли. 3) Выполняем нужные команды, вывод которых необходимо скопировать. 4) Ctrl+A, Ctrl+[ - мы в режиме копирования. Ставим курсор на начало выделения, жмём пробел, потом ставим курсор на конец выделения, жмём пробел. Текст скопирован в буфер. 5) Ctrl+A, с - мы создали новое 1-е окно. 6) Ctrl+A, 1 - мы перешли на 1-е окно. 7) Открываем любой (?) текстовый редактор (я пробовал в mc), и жмём Ctrl+A, Ctrl+] - текст вставлен. Сохраняем. 8) Ctrl+A, Ctrl+0 - вернуться обратно в нулевое окно. Первым решением будет увеличить дефолтный (умолчальный) размер буфера в исходниках ядра и перекомпилировать его. Позвольте предположить, что вы столь же не склонны заниматься этим, как и я, и поискать средство более гибкое. И такое средство есть, а называется оно framebuffer console
, для краткости fbcon
. Это устройство имеет файл документации fbcon.txt
; если вы устанавливали документацию к ядру, то он у вас есть. Выискивайте его где-то в районе /usr/share
ветви (я не могу указать точный путь из-за разницы в дистрибутивах). На этом месте прошу прощения: мы должны сделать небольшое отступление и немного поговорить о видеобуфере (framebuffer
). Видеобуфер - это буфер между дисплеем и видеоадаптером. Его прелесть в том, что им можно манипулировать: он позволяет трюки, которые не прошли бы, будь адаптер связан напрямую с дисплеем. Один из таких трюков связан с буфером прокрутки; оказывается, вы можете "попросить" видеобуфер выделить больше памяти буферу прокрутки. Достигается это через загрузочные параметры ядра. Сначала вы требуете framebuffer
(видеобуфер); Затем запрашиваете больший буфер прокрутки. Нижеследующий пример касается GRUB
, но может быть легко адаптирован к LILO
. В файле настройки GRUB
- menu.lst
- найдите соответствующую ядру строчку, и затем:
Удалите опцию vga=xxx
, если таковая присутствует.
Добавьте опцию video=vesabf
или то, что соответствует вашему "железу".
Добавьте опцию fbcon=scrollback:128
.
После этой процедуры, строка параметров ядра должна выглядеть приблизительно так: Kernel /vmlinuz root=/dev/sdb5 video=radeonfb fbcon=scrollback:128
Спрашивается, зачем удалять опцию vga=xxx
? Из-за возможных конфликтов с видео-опцией. На своем ATI адаптере, я не могу изменить буфер прокрутки, если vga=xxx
присутствует в списке. Возможно в вашем случае это не так. Если вышеперечисленные опции работают - хорошо; но что, если вы хотите увеличить число строк, или установить более мелкий шрифт на экране? Вы всегда делали это при помощи опции vga=xxx
- а она-то и исчезла. Не переживайте - то же самое может быть достигнуто изменением параметров fbcon, как описано в файле fbcon.txt
(но не описано в данной статье). С опцией fbcon=scrollback:128
у меня буфер прокрутки увеличился до 17 экранов (35 раз Shift+PgUp по полэкрана).
Кстати, 128 - это килобайт. Автор статьи утверждает, что больше установить нельзя. Я и не пробовал. Можно заюзать script
. Script filename.log
когда все нужные команды выполнены - Все записано в filename.log В FreeBSD есть замечательная утилита watch, которая позволяет мониторить терминалы, но как оказалось, в Linux она выполняет совсем иные функции =\ Стоит погуглить на эту тему, чего-нть да найдется...


Использование тоннелей


Выводы
Иногда что-то надо показать на экране, а что-то - записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит - научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.Стандартные дескрипторы файлов
Всё в Linux - это файлы, в том числе - ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.STDIN
STDIN - это стандартный поток ввода оболочки. Для терминала стандартный ввод - это клавиатура. Когда в сценариях используют символ перенаправления ввода - < , Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.STDOUT
STDOUT - стандартный поток вывода оболочки. По умолчанию это - экран. Большинство bash-команд выводят данные в STDOUT , что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >> .
То, что выведет pwd , будет добавлено к файлу myfile , при этом уже имеющиеся в нём данные никуда не денутся.
После выполнения этой команды мы увидим сообщения об ошибках на экране.
Попытка обращения к несуществующему файлу
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT , именно поэтому при возникновении ошибки мы видим сообщение на экране.▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR - 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
Сообщение об ошибке теперь попадёт в файл myfile .
Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
Перенаправление ошибок и стандартного вывода
Перенаправление STDERR и STDOUT в один и тот же файл
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR . Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR , при этом перед номером дескриптора надо поставить символ амперсанда (&):
Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.
Временное перенаправление
Как видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec:
Запустим скрипт.
Перенаправление всего вывода в файл
Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
Перенаправление вывода в разные файлы
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile , а не обычный STDIN . Посмотрим на перенаправление ввода в действии:
Вот что появится на экране после запуска скрипта.
Перенаправление ввода
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
После запуска скрипта часть вывода попадёт на экран, часть - в файл с дескриптором 3 .
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
Испытаем сценарий.
Перенаправление ввода
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &- . Выглядит это так:
После исполнения скрипта мы получим сообщение об ошибке.
Попытка обращения к закрытому дескриптору файла
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof . Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin . Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$ , в которую оболочка записывает текущий PID .
Вывод сведений об открытых дескрипторах
Вот что получится, если этот скрипт запустить.
Просмотр дескрипторов файлов, открытых скриптом
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null . Это - что-то вроде «чёрной дыры».
Тот же подход используется, если, например, надо очистить файл, не удаляя его:Итоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
$ cd /dev
$ ls -l
onsole
пульт управления системы
dsk
порции на диске
fd0
флоппи-диск 1
mem память
lр принтер
lр0
параллельный порт 0
. . .
root
порция на диске для корневой файловой системы
swap
своп-порция
syscon
альтернативное имя пульта
systty
еще одно имя для системной консоли
term
директория для терминалов
ttyS0
серийный порт 0 (COM1)
. . .
Индексный
дескриптор специального файла содержит информацию о классе устройства, его типе
и номере. Класс устройства определяет устройства с посимвольным обменом и с
поблочным обменом. Примером устройства с посимвольным обменом может служить
клавиатура. Специальные файлы, обеспечивающие связь с устройствами такого типа,
называют байт-ориентированными. Для блочных устройств характерен обмен большими
блоками информации, это ускоряет обмен и делает его более эффективным. Все
дисковые устройства поддерживают блочный обмен, а специальные файлы,
обслуживающие их, называют блок-ориентированными. Специальные файлы не содержат
какой-либо символьной информации, поэтому в листинге каталога их длина не
указывается.
монтированием
/dev/dsk/os1
монтирования
/dev/dsk/os1 как /usr/
#/sbin/mount/dev/dsk/osl/usr1
монтирует /dev/dsk/osl на /usr1
#/sbin/mount/dev/dsk/flt/а
монтирует /dev/dsk/flt на /а
Каталог,
к которому прикрепляется монтируемая файловая система, должен быть в данный
момент пустой, так как содержимое его будет недоступно, пока файловая система
монтируется.
#
/sbin/umount /b
#
/sbin/umount /dev/dsk/0s2
В LINUX
дисковые устройства имеют своеобразные обозначения. В LINUX пользователь
никогда не сталкивается с проблемой точного указания физического устройства, на
котором располагается информация. В LINUX произвольное число внешних устройств
может быть очень большим, поэтому, пользователь имеет дело только с именем
каталога, в котором находятся нужные ему файлы. Все файловые системы монтируются
один раз, как правило, при загрузке системы. На некоторые каталоги могут быть
смонтированы файловые системы и с удаленных компьютеров.
$ 1s
/dev/dsk
0s0 1s0
c0t0d0s0 c0tld0s0 f0 f05q f13dt fld8d
0sl 1sl
c0t0d0sl c0tld0sl f03d f05qt f13h fld8dt
0s2 1s2
c0t0d0s2 c0tld0s2 f03dt f0d8d f13ht fld8t
. . .
$
с
controller d disk s section
Так, 0s0
обычно эквивалентно c0t0d0s0, а 0sl - c0t0d0sl, и трехсимвольные имена секций -
это просто сокращение для дискового контроллера с номером 0.
$ 1s
/dev/rmt
c0s0 cls0
c3s0 ntape ntapel tape tapelКак увеличить буфер обратной прокрутки?