Introduktion
För att skriva ett examensarbete valde jag ämnet "Informationsbehandlingsteknologier". Jag anser att detta ämne är det mest relevanta, eftersom information är medveten information om världen omkring oss, som är föremål för lagring, transformation, överföring och användning. All mänsklig aktivitet är en process för att samla in och bearbeta information, fatta beslut baserat på den och implementera dem. Med tillkomsten av modern datorteknik började information fungera som en av de viktigaste resurserna för vetenskapliga och tekniska framsteg.
Information är kunskap som uttrycks i signaler, meddelanden, nyheter, notiser m.m. Varje människa i världen är omgiven av ett hav av information av olika slag.
Syftet med mitt examensarbete är att studera principerna för informationsbehandling i dess presentationsform, sätt att koda och lagra den. För att göra detta är det nödvändigt att studera begreppet information, som är det grundläggande begreppet datavetenskap.
För en mer detaljerad studie av detta ämne måste arbetet delas upp i flera steg. För det första att bekanta sig med begreppet "informationsbehandling", nämligen att studera: mål, mål och typer av informationsbehandling; metoder för informationsbearbetning; system för informationsbehandling; moderna informationsbehandlingssystem; problem associerade med datormetoder för informationsbehandling; skillnader mellan datordatabehandling och icke-automatiserad; teknisk process för informationsbehandling. För det andra att undersöka klassificeringen av tekniska medel för databehandling. Dessa inkluderar: databehandlingslägen; metoder för databehandling; komplex av tekniska medel för informationsbehandling; klassificering av tekniska medel för informationsbehandling.
1. Informationsbehandling
Main typer av information enligt dess representationsform, sätt att koda och lagra den är det som är av största vikt för datavetenskap:
§ grafisk eller figurativ- den första typen, för vilken en metod för att lagra information om världen runt implementerades i form av hällmålningar, och senare i form av målningar, fotografier, diagram, ritningar på papper, duk, marmor och andra material som visar bilder av den verkliga världen;
§ ljud- världen omkring oss är full av ljud och problemet med deras lagring och replikering löstes med uppfinningen av ljudinspelningsenheter 1877. Musikalisk information är dess variation - för denna typ uppfanns en kodningsmetod med hjälp av specialtecken, vilket gör det är möjligt att lagra den på samma sätt som grafisk information;
§ text-- ett sätt att koda mänskligt tal med specialtecken - bokstäver och olika folk har olika språk och använder olika uppsättningar bokstäver för att visa tal; denna metod blev särskilt viktig efter uppfinningen av papper och tryckning;
§ numerisk- kvantitativt mått på föremål och deras egenskaper i omvärlden; fick särskilt stor betydelse med utvecklingen av handel, ekonomi och penningväxling; på samma sätt som textinformation, för att visa den, används kodningsmetoden med specialtecken - siffror, och kodsystemen (siffrorna) kan vara olika;
§ videoinformation- ett sätt att bevara "live" bilder av världen omkring oss, som dök upp med uppfinningen av filmen.
Det finns också typer av information för vilka inga metoder för kodning och lagring ännu har uppfunnits - detta är taktil information som överförs av förnimmelser, organoleptisk, överförd av lukter och smaker, etc.
Claude Shannon anses vara skaparen av allmän informationsteori och grundaren av digital kommunikation. Han blev världsberömd med sitt grundläggande arbete från 1948 - A Mathematical Theory of Communication, som för första gången underbygger möjligheten att använda en binär kod för att överföra information.
Enheten av lagarna för informationsbehandling i system av olika natur (fysisk, ekonomisk, biologisk, etc.) är den grundläggande grunden för teorin om informationsprocesser, som bestämmer dess allmänna giltighet och specificitet. Studieobjektet för denna teori är information - begreppet är till stor del abstrakt, existerar "i sig" utan samband med det specifika kunskapsområde där det används.
Informationsresurser i det moderna samhället spelar ingen mindre och ofta mer roll än materiella resurser. Att veta vem, när och var man ska sälja en produkt kan vara lika värdefullt som själva produkten. I detta avseende tilldelas metoderna för informationsbehandling en stor roll. Det finns fler och fler avancerade datorer, nya, bekväma program, moderna metoder för att lagra, överföra och skydda information.
Ur marknadens synvinkel har information länge blivit en handelsvara, och denna omständighet kräver intensiv utveckling av praxis, industri och teorin om samhällets datorisering. Datorn som informationsmiljö gjorde det inte bara möjligt att göra ett kvalitativt steg i organisationen av industri, vetenskap och marknad, utan den definierade nya självvärdefulla produktionsområden: datateknik, telekommunikation, mjukvaruprodukter.
Trender i datoriseringen av samhället är förknippade med uppkomsten av nya yrken relaterade till datateknik och olika kategorier av datoranvändare. Om detta område på 60-70-talet dominerades av datorspecialister (elektronikingenjörer och programmerare), som skapar ny datorutrustning och nya programvarupaket, expanderar idag kategorin datoranvändare intensivt - representanter för olika kunskapsområden som inte är specialister på datorer i snäv mening, men kan använda dem för att lösa sina specifika problem.
Figur 1.1 Informationsbehandlingscykel
En datoranvändare ska känna till de allmänna principerna för att organisera informationsprocesser i en datormiljö, kunna välja de informationssystem och tekniska medel han behöver och snabbt bemästra dem i förhållande till sitt ämnesområde.
1.1 Mål, uppgifter och typer av informationsbehandling
Informationsprocesser(insamling, bearbetning och överföring av information) har alltid spelat en viktig roll inom vetenskap, teknik och samhälle. Under mänsklighetens utveckling finns det en stadig trend mot automatisering av dessa processer, även om deras interna innehåll i huvudsak har förblivit oförändrat.
Insamling av information- detta är ämnets aktivitet, under vilken han får information om föremålet av intresse för honom.
Insamlingen av information kan utföras antingen av en person eller med hjälp av tekniska medel och system - hårdvara. Till exempel kan användaren få information om tåg eller flygs rörelser själv, efter att ha studerat tidtabellen, eller från en annan person direkt, eller genom vissa dokument sammanställda av denna person, eller med hjälp av tekniska medel (automatisk information, telefon, etc.) . Uppgiften att samla in information kan inte lösas isolerat från andra uppgifter, i synnerhet uppgiften att utbyta information (överföring).
Informationsutbyteär en process under vilken informationskällan sänder den och mottagaren tar emot den.
Om fel hittas i de överförda meddelandena, organiseras återsändningen av denna information. Som ett resultat av informationsutbytet mellan källan och mottagaren upprättas ett slags ”informationsbalans”, där mottagaren i idealfallet kommer att ha samma information som källan.
Utbytet av information sker med hjälp av signaler, som är dess materiella bärare. Informationskällor kan vara alla objekt i den verkliga världen som har vissa egenskaper och förmågor. Om ett föremål tillhör den livlösa naturen, genererar det signaler som direkt återspeglar dess egenskaper. Om källobjektet är en person, kan signalerna som genereras av honom inte bara direkt återspegla hans egenskaper, utan också motsvara de tecken som en person utvecklar för att utbyta information.
Den mottagna informationen kan användas upprepade gånger av mottagaren. För detta ändamål måste han fixa det på en materialbärare (magnetisk, foto, film, etc.).
Ansamling av information- detta är processen för att bilda den initiala, osystematiserade uppsättningen av information.
Inspelade signaler kan inkludera de som återspeglar värdefull eller ofta använd information. En del av informationen vid en given tidpunkt kanske inte är av särskilt värde, även om det kan krävas i framtiden.
Datalagring- detta är processen att behålla den ursprungliga informationen i en form som säkerställer att data utfärdas på begäran av slutanvändare i tid.
Databehandlingär en ordnad process för dess omvandling i enlighet med algoritmen för att lösa problemet.
Efter att ha löst problemet med informationsbehandling måste resultatet utfärdas till slutanvändare i den form som krävs. Denna operation implementeras för att lösa problemet med att utfärda information. Utfärdandet av information sker som regel med hjälp av externa datorenheter i form av texter, tabeller, grafer etc.
Informationsegenskaper.
Som alla objekt har information egenskaper. Ett karakteristiskt särdrag för information från andra natur- och samhällsobjekt är dualism: informationens egenskaper påverkas av både egenskaperna hos de initiala data som utgör dess innehåll och egenskaperna hos de metoder som registrerar denna information.
Ur informatikens synvinkel tycks följande generella kvalitativa egenskaper vara de viktigaste: objektivitet, tillförlitlighet, fullständighet, noggrannhet, relevans, användbarhet, värde, aktualitet, förståelighet, tillgänglighet, korthet, etc.
Informationens objektivitet . Objektiv - existerande utanför och oberoende av mänskligt medvetande. Information är en återspegling av den yttre objektiva världen. Information är objektiv om den inte beror på metoderna för dess fixering, någons åsikt, omdöme.
Exempel. Meddelandet "Det är varmt ute" bär subjektiv information, och meddelandet "Det är 22 °C ute" är objektivt, men med en noggrannhet som beror på mätinstrumentets fel.
Objektiv information kan erhållas med hjälp av funktionsdugliga sensorer, mätinstrument. Återspeglas i en persons sinne kan information förvrängas (i större eller mindre utsträckning) beroende på åsikt, omdöme, erfarenhet, kunskap om ett visst ämne, och därmed upphöra att vara objektiv.
Pålitlighet information . Information är tillförlitlig om den återspeglar det verkliga tillståndet. Objektiv information är alltid tillförlitlig, men tillförlitlig information kan vara både objektiv och subjektiv. Pålitlig information hjälper oss att fatta rätt beslut. Felaktig information kan bero på följande orsaker:
§ avsiktlig förvrängning (desinformation) eller oavsiktlig förvrängning av en subjektiv egenskap;
§ förvrängning till följd av störningar (”skadad telefon”) och otillräckligt exakta sätt att åtgärda det.
Informationens fullständighet . Information kan kallas fullständig om den är tillräcklig för förståelse och beslutsfattande. Ofullständig information kan leda till en felaktig slutsats eller ett felaktigt beslut.
Informationsnoggrannhet bestäms av graden av dess närhet till det verkliga tillståndet för objektet, processen, fenomenet etc.
Informationens relevans - betydelse för nutid, aktualitet, brådska. Endast information som tas emot i rätt tid kan vara användbar.
Användbarhet (värde) av information . Nyttan kan bedömas i förhållande till dess specifika konsumenters behov och utvärderas efter de uppgifter som kan lösas med dess hjälp.
Den mest värdefulla informationen är objektiv, pålitlig, fullständig och uppdaterad. Samtidigt bör man komma ihåg att partisk, opålitlig information (till exempel fiktion) är av stor betydelse för en person. Social (offentlig) information har också ytterligare egenskaper:
§ har en semantisk (semantisk) karaktär, d.v.s. konceptuella, eftersom det är i begrepp som de mest väsentliga egenskaperna hos objekt, processer och fenomen i omvärlden generaliseras.
§ har en språklig karaktär (förutom vissa typer av estetisk information, till exempel konst). Samma innehåll kan uttryckas på olika naturliga (vardagsspråk) skrivna i form av matematiska formler etc.
Med tiden växer informationsmängden, information ackumuleras, den systematiseras, utvärderas och generaliseras. Denna egenskap kallades tillväxt och ackumulering av information. (Kumulation - från latin cumulatio - ökning, ackumulering).
Informationsåldrande är minskningen av dess värde över tid. Det är inte tiden i sig som åldrar information, utan uppkomsten av ny information som förtydligar, kompletterar eller avvisar, helt eller delvis, den tidigare. Vetenskaplig och teknisk information åldras snabbare, estetisk (konstverk) - långsammare.
Logik, kompakthet, bekväm presentationsform underlättar förståelsen och assimileringen av information.
Begreppet informationsbehandling är mycket brett. På tal om informationsbehandling är det nödvändigt att ge begreppet bearbetning invariant. Vanligtvis är det innebörden av meddelandet (innebörden av informationen i meddelandet). Vid automatiserad informationsbehandling är bearbetningsobjektet ett meddelande och här är det viktigt att utföra bearbetningen på ett sådant sätt att meddelandetransformationernas invarianter motsvarar informationstransformationens invarianter.
Syftet med informationsbehandlingen som helhet bestäms av syftet med ett visst system som den aktuella informationsprocessen är förknippad med. Men för att uppnå målet måste man alltid lösa ett antal sammanhängande uppgifter.
Till exempel är det inledande skedet av informationsprocessen mottagning. I olika informationssystem uttrycks mottagning i sådana specifika processer som urval av information (i system av vetenskaplig och teknisk information), omvandling av fysiska storheter till en mätsignal (i informations- och mätsystem) och irritabilitet. och förnimmelser (i biologiska system) etc.
Mottagningsprocessen börjar vid gränsen som skiljer informationssystemet från omvärlden. Här, vid gränsen, omvandlas signalen från omvärlden till en form som är lämplig för vidare bearbetning. För biologiska system och många tekniska system, såsom läsautomater, är denna gräns mer eller mindre tydligt definierad. I andra fall är det till stor del villkorat och till och med vagt. När det gäller den interna gränsen för mottagningsprocessen är den nästan alltid villkorad och väljs i varje specifikt fall baserat på bekvämligheten med att studera informationsprocessen.
Det bör noteras att oavsett hur "djupt" den inre gränsen förs tillbaka så kan mottagande alltid ses som en klassificeringsprocess.
Formaliserad informationsbearbetningsmodell
Låt oss nu gå över till frågan om vilka likheter och skillnader finns i förknippade med olika komponenter i informationsprocessen, med hjälp av en formaliserad bearbetningsmodell. Först och främst noterar vi att denna fråga inte kan separeras från konsumenten av information (adresserat), från de semantiska och pragmatiska aspekterna av information. Närvaron av adressaten för vilken meddelandet (signalen) är avsett avgör frånvaron av en en-till-en-korrespondens mellan meddelandet och informationen i det. Det är ganska uppenbart att samma budskap kan ha olika betydelser för olika mottagare och olika pragmatiska betydelser.
· Det allmänna schemat för.
· Redogörelse för uppgiften att bearbeta.
· Bearbetningsexekutor.
· Bearbetningsalgoritm.
· Typiska uppgifter för informationsbehandling.
1.2 Informationsbehandlingsmetoder
Det finns många metoder för informationsbearbetning, men i de flesta fall handlar de om bearbetning av textuella, numeriska och grafiska data.
Textinformationsbehandling
Textinformation kan härröra från olika källor och ha olika grad av komplexitet i form av presentation. Beroende på presentationsformen används en mängd olika informationstekniker för att bearbeta textmeddelanden. Oftast används textredigerare eller processorer som ett verktyg för att bearbeta elektronisk textinformation. De representerar en mjukvaruprodukt som förser användaren med specialverktyg utformade för att skapa, bearbeta och lagra textinformation. Textredigerare och processorer används för att komponera, redigera och bearbeta olika typer av information. Skillnaden mellan textredigerare och processorer är att redigerare som regel är utformade för att endast fungera med en viss typ av information (texter, formler etc.), medan processorer tillåter användning av andra typer av information.
Redaktörer utformade för att förbereda texter kan villkorligt delas in i vanliga (förberedelse av brev och andra enkla dokument) och komplexa (formatering av dokument med olika typsnitt, inklusive grafik, ritningar, etc.). Redaktörer som används för automatiserat arbete med text kan delas in i flera typer: enkla, integrerade, hypertextredigerare, textigenkännare, redaktörer av vetenskapliga texter, publiceringssystem.
I de enklaste formateringsredigerarna (till exempel Anteckningar) används inte ytterligare koder för den interna representationen av text, medan texter vanligtvis bildas baserat på tecknen i ASCII-kodtabellen. Ordbehandlare representerar ett textförberedelsesystem (ordbehandlare). Den mest populära bland dem är MS Word.
Tekniken för att bearbeta textinformation med hjälp av sådana program inkluderar vanligtvis följande steg:
) skapa en fil för att lagra textinformation;
) bevarande av den inlämnade texten i elektronisk form;
) öppna en fil som lagrar textinformation;
) redigering av elektronisk textinformation;
) formatering av text lagrad i elektronisk form;
) skapa textfiler baserat på inbyggd text
stilredigerare;
) automatisk bildande av en innehållsförteckning till texten och en alfabetisk uppslagsbok;
) automatisk stavnings- och grammatikkontroll;
) bädda in olika element och objekt i texten;
) konsolidering av dokument;
) skriva ut text.
De huvudsakliga redigeringsoperationerna inkluderar: lägga till; avlägsnande; rör på sig; kopiering av ett fragment av text, samt sökning och kontextuell ersättning. Om texten du skapar representerar ett flersidigt dokument kan du använda sid- eller avsnittsformatering. Samtidigt kommer sådana strukturella element som: bokmärken, fotnoter, korsreferenser och sidhuvuden och sidfötter att dyka upp i texten.
De flesta ordbehandlare stöder konceptet med ett sammansatt dokument, en behållare som innehåller olika objekt. Det låter dig infoga figurer, tabeller, grafik som framställts i andra mjukvarumiljöer i texten i ett dokument. Används i detta teknik för kommunikation och implementering av objekt kallad OLE(Object Linking and Embedding - kommunikation och implementering av objekt).
För att automatisera exekveringen av ofta upprepade åtgärder i ordbehandlare används makron. Det enklaste makrot är en inspelad sekvens av tangenttryckningar, rörelser och musklick. Den kan spelas upp som en bandinspelning. Det kan bearbetas och modifieras genom att lägga till standardmakron.
Överföringen av texter från en textredigerare till en annan utförs av programmet- omvandlare. Det skapar en utdatafil i lämpligt format. Vanligtvis har ordbehandlingsprogram inbyggda moduler för att konvertera populära filformat.
Typer av ordbehandlare är desktop publishing system. De kan förbereda material enligt reglerna för tryckning. Desktop publishing-program (till exempel Publishing, PageMaker) är ett verktyg för en layoutdesigner, designer och teknisk redaktör. Med deras hjälp kan du enkelt ändra format och numrering av sidor, storlek på indrag, kombinera olika typsnitt etc. I större utsträckning är de avsedda för publicering av tryckta produkter.
Databehandling i tabellform
Användare i arbetet måste ofta hantera tabelldata i processen att skapa och underhålla bokföringsböcker, bankkonton, uppskattningar, utdrag, när de upprättar planer och allokerar organisationsresurser, när de utför vetenskaplig forskning. Önskan att automatisera denna typ av arbete har lett till framväxten av specialiserad programvara för att bearbeta information som presenteras i tabellform. Sådan programvara kallas kalkylbladsprocessorer eller kalkylblad. Sådana program tillåter inte bara att skapa tabeller utan också att automatisera behandlingen av tabelldata.
Kalkylblad visade sig vara effektiva för att lösa sådana problem som: sortering och bearbetning av statistiska data, optimering, prognoser, etc. Med deras hjälp löses uppgifterna med beräkningar, beslutsstöd, modellering och presentation av resultat inom nästan alla verksamhetsområden. När du arbetar med tabelldata utför användaren ett antal typiska procedurer, till exempel, såsom:
) skapa och redigera tabeller;
) skapande (sparande) av en tabellfil;
) mata in och redigera data i cellerna i tabellen;
) bädda in olika element och objekt i tabellen;
a) användning av ark, formatering och länkning av tabeller;
) databehandling i tabellform med formler och
speciella funktioner;
) konstruktion av diagram och grafer;
) behandling av uppgifter som presenteras i form av en lista;
) analytisk databehandling;
) skriv ut tabeller och diagram till dem.
Tabellens struktur inkluderar numrering och tematiska rubriker, ett huvud (rubrik), ett sidofält (den första kolumnen i tabellen som innehåller radrubriker) och en prograf (tabellens faktiska data).
Den mest populära bland kalkylbladsprocessorer är MS Excel. Den ger användarna en uppsättning kalkylblad (sidor), i vilka en eller flera tabeller kan skapas.
Kalkylbladet innehåller en uppsättning celler som bildar en rektangulär matris. Deras koordinater bestäms genom att ange den vertikala positionen (i kolumner) och den horisontella positionen (i rader). Ett ark kan innehålla upp till 256 kolumner och upp till 65536 rader. Kolumner indikeras med bokstäver i det latinska alfabetet: A, B, C ... Z, AA, AB, AC ... AZ, BA, BB ... och rader - med siffror. Så, till exempel, "D14" betecknar cellen i skärningspunkten mellan kolumn "D" och rad 14, och "CD99" cellen i skärningspunkten mellan kolumn "CD" och rad 99. Kolumnnamnen visas alltid på den översta raden i kalkylbladet och radnumren i kalkylbladets vänstra kant.
Följande operationer definieras för kalkylarksobjekt: redigera, slå samman till en grupp, ta bort, rensa, infoga, kopiera. Operationen att flytta ett fragment reduceras till sekventiell exekvering av raderings- och infogningsoperationer.
För att underlätta beräkningar är matematiska, statistiska, finansiella, logiska och andra funktioner inbyggda i kalkylbladsprocessorer. Från de numeriska värdena som anges i tabellerna kan du bygga olika tvådimensionella, tredimensionella och blandade diagram (mer än 20 typer och undertyper).
Tabellprocessorer kan utföra databasfunktioner. I det här fallet matas data in i tabellerna på samma sätt som i databasen, det vill säga genom skärmformuläret. Data i dem kan skyddas, sorteras med en nyckel eller med flera nycklar. Dessutom utförs bearbetning av frågor till databasen och bearbetning av externa databaser, skapande av pivottabeller etc. De kan även använda det inbyggda makroprogrammeringsspråket.
En viktig egenskap hos tabeller är förmågan att använda formler och funktioner i dem. Formeln kan innehålla referenser till tabellceller som bland annat finns på ett annat kalkylblad eller i en tabell som finns i en annan fil. Excel erbjuder över 200 förprogrammerade formler som kallas funktioner. För att underlätta orienteringen i dem är funktionerna indelade i kategorier. Med hjälp av "Funktionsguiden" kan du skapa dem när som helst i arbetet.
Kalkylarksredigerare Excel, textredigerare Word och andra program som ingår i applikationspaketet (APP) Office stöder OLE-datautbytesstandarden, och användningen av "listor" gör att du kan arbeta effektivt med stora homogena datamängder. En liknande OLE-mekanism används i andra PPP.
I Excel kan du effektivt bearbeta olika ekonomiska och statistiska data.
Bearbetning av grafisk information
Grafisk information på en datorskärm bildas skärmen av prickar.
I grafikläge representerar skärmen en uppsättning lysande punkter - pixlar ("pixel", från det engelska "bildelementet"). Det totala antalet punkter på skärmen kallas bildskärmens upplösning, vilket också beror på dess typ och funktionssätt. Måttenheten i detta fall är antalet punkter per tum (dpi). Upplösningen på moderna skärmar är vanligtvis 1280 punkter horisontellt och 1024 punkter vertikalt, d.v.s. 1310720 poäng.
Antalet färger som reflekteras beror på kapaciteten hos videoadaptern och skärmen. Det kan ändras med programvara. Varje färg representerar ett av punkttillstånden på skärmen. Färgbilder har lägen: 16, 256, 65536 (hög färg) och 16 777 216 färger (äkta färg).
Vilken datorbild som helst består av en uppsättning grafiska primitiver som återspeglar något grafiskt element. Primitiver kan också vara alfanumeriska och andra tecken.
1.3 Informationsbehandlingsschema
Initial information - bearbetningsutövare - sammanfattande information.
I processen för informationsbearbetning löses ett informationsproblem, som preliminärt kan ställas in i traditionell form: en viss uppsättning initiala data ges, det krävs för att få några resultat. Själva processen för övergång från källdata till resultatet är processen för bearbetning. Objektet eller subjektet som utför bearbetningen kallas bearbetningsutövaren.
För att framgångsrikt utföra informationsbearbetning måste utföraren (personen eller enheten) känna till bearbetningsalgoritmen, d.v.s. en sekvens av åtgärder som måste följas för att uppnå önskat resultat.
Det finns två typer av informationsbehandling. Den första typen av bearbetning: bearbetning i samband med att få ny information, nytt innehåll av kunskap (lösa matematiska problem, analysera situationen, etc.). Andra typen av bearbetning: bearbetning relaterad till att ändra formen, men inte att ändra innehållet (till exempel att översätta text från ett språk till ett annat).
En viktig typ av informationsbehandling är kodning- omvandling av information till en symbolisk form, bekväm för dess lagring, överföring, bearbetning. Kodning används aktivt i tekniska sätt att arbeta med information (telegraf, radio, datorer). En annan typ av informationsbehandling är strukturering data (införande av en viss ordning i informationslagring, klassificering, katalogisering av data).
En annan typ av informationsbehandling är Sök i något informationslager av nödvändig data som uppfyller vissa sökvillkor (begäran). Sökalgoritmen beror på hur informationen är organiserad.

Figur 1.3.1 Schema för informationsbehandling
1.4 Moderna informationsbehandlingssystem
När de utformar tekniska processer styrs de av sätten för deras implementering. Metoden för implementering av tekniken beror på volymen och tidsfunktionerna för de uppgifter som ska lösas: periodicitet och brådska, krav på hastigheten för meddelandebehandling, såväl som på regimens kapacitet hos tekniska medel, och i första hand datorer.
Det finns: batchläge; realtidsläge; tidsdelningsläge; regleringssystem; begäran; dialog; telebearbetning; interaktiv; enda program; multiprogram (multi-processing).
För användare av ekonomi- och kreditsystemet är följande mest relevanta: lägen: batch, interaktiv och realtid.
batch-läge. När du använder detta läge har användaren inte direkt kommunikation med datorn. Insamling och registrering av information, inmatning och bearbetning sammanfaller inte i tid. Först samlar användaren in information och formar den till paket i enlighet med typen av uppgifter eller något annat tecken. (Det är i regel uppgifter av icke-operativ karaktär, med en långsiktig giltighet av lösningens resultat). Efter att mottagningen av informationen är klar, matas den in och bearbetas, sålunda uppstår en behandlingsfördröjning. Detta läge används som regel med en centraliserad metod för informationsbehandling.
Dialogläge (frågeläge)., där det är möjligt för användaren att direkt interagera med datorsystemet under användarens arbete. Databehandlingsprogram lagras permanent i datorns minne om datorn är tillgänglig när som helst, eller under en viss tidsperiod då datorn är tillgänglig för användaren. En användares interaktion med ett datorsystem i form av en dialog kan vara mångfacetterad och bestämmas av olika faktorer: kommunikationsspråket, användarens aktiva eller passiva roll; vem är initiativtagaren till dialogen - användaren eller datorn; respons tid; dialogstruktur m.m. Om initiativtagaren till dialogen är användaren måste han ha kunskap om att arbeta med procedurer, dataformat etc. Om initiativtagaren är en dator, så berättar maskinen själv vid varje steg vad den ska göra med de olika valmöjligheterna. Denna funktionsmetod kallas "menyval". Den ger stöd för användaråtgärder och föreskriver deras sekvens. I det här fallet krävs mindre utbildning av användaren.
Det interaktiva läget kräver en viss nivå av teknisk utrustning av användaren, dvs. närvaron av en terminal eller PC ansluten till det centrala datorsystemet via kommunikationskanaler. Detta läge används för att komma åt information, datorer eller programvaruresurser. Möjligheten att arbeta i ett interaktivt läge kan vara begränsad vad gäller start- och sluttid för arbetet, eller så kan den vara obegränsad.
Realtidsläge betyder ett datorsystems förmåga att interagera med kontrollerade eller hanterade processer i samma takt som dessa processer. Datorns reaktionstid måste tillgodose takten i den kontrollerade processen eller användarnas krav och har minsta fördröjning. Som regel används detta läge vid decentraliserad och distribuerad databehandling. Exempel: en PC installeras på operatörens skrivbord, genom vilken all information om transaktioner läggs in i datorn när den blir tillgänglig.
Det följande databehandlingsmetoder:
centraliserad, decentraliserad, distribuerad och integrerad.
Centraliserad antar närvaron av VC. Med denna metod levererar användaren den initiala informationen till CC och tar emot resultatet av behandlingen i form av effektiva dokument. En egenskap hos denna bearbetningsmetod är komplexiteten och mödosamma för att upprätta en snabb, oavbruten anslutning, en stor arbetsbelastning av CC-information (eftersom dess volym är stor), reglering av tidpunkten för operationer, organisation av systemsäkerhet från eventuell obehörig åtkomst.
decentraliserat behandling. Denna metod är förknippad med uppkomsten av datorer, som gör det möjligt att automatisera en specifik arbetsplats. Det finns för närvarande tre typer av decentraliserad databehandlingsteknik.
Den första är baserad på persondatorer som inte är anslutna till ett lokalt nätverk. (data lagras i separata filer och på separata diskar). För att få indikatorer skrivs informationen om till en dator. Nackdelar: bristande sammankoppling av uppgifter, oförmåga att bearbeta stora mängder information, lågt skydd mot obehörig åtkomst.
För det andra: PC-datorer anslutna till ett lokalt nätverk, vilket leder till skapandet av enskilda datafiler (men det är inte designat för stora mängder information).
För det tredje: PC-datorer anslutna till ett lokalt nätverk, som inkluderar specialservrar (med "klient-server"-läget).
Distribuerad metoden för databehandling bygger på fördelningen av bearbetningsfunktioner mellan olika datorer som ingår i nätverket. Denna metod kan implementeras på två sätt: det första innebär att en dator installeras i varje nätverksnod (eller på varje nivå i systemet), medan databehandling utförs av en eller flera datorer, beroende på systemets faktiska kapacitet och dess behov för närvarande. Det andra sättet är att placera ett stort antal olika processorer i ett system. Detta sätt används i bank- och finansiell informationsbehandlingssystem, där ett databearbetningsnätverk behövs (filialer, avdelningar, etc.). Fördelar med den distribuerade metoden: förmågan att bearbeta vilken mängd data som helst inom en given tidsram; hög grad av tillförlitlighet, eftersom det i händelse av fel på ett tekniskt medel är möjligt att omedelbart ersätta det med ett annat; minskning av tid och kostnader för dataöverföring; öka flexibiliteten i systemen, förenkla utvecklingen och driften av mjukvara m.m. Den distribuerade metoden bygger på ett komplex av specialiserade processorer, d.v.s. varje dator är designad för att lösa vissa uppgifter, eller uppgifter på dess nivå
Nästa sätt att behandla data är integrerad . Det sörjer för skapandet informationsmodell hanterat objekt, det vill säga skapandet av en distribuerad databas. Denna metod ger maximal bekvämlighet för användaren. Å ena sidan tillhandahåller databaser kollektiv användning och centraliserad hantering. Å andra sidan kräver mängden information, mångfalden av uppgifter som ska lösas distribution av databasen. Tekniken för integrerad informationsbehandling gör det möjligt att förbättra kvaliteten, tillförlitligheten och hastigheten för behandlingen, eftersom behandlingen utförs på basis av en enda informationsmatris, när den väl har matats in i datorn. En egenskap hos denna metod är den tekniska och tidsmässiga separationen av bearbetningsförfarandet från förfarandena för insamling, förberedelse och inmatning av data.
Moderna informationsbehandlingssystem använder digital teknik som utesluter pappersmedia och utbyter data över ett nätverk mellan arbetsstationer. Teknologier innebär också gemensamma ansträngningar från en grupp anställda för att lösa ett problem (d.v.s. organisera en arbetsgrupp i ett nätverk), utbyte av åsikter i under diskussionen på nätverket av någon fråga i realtid (telekonferens), det snabba utbytet av material genom e-post, anslagstavlor osv. För sådana system, som täcker företagets arbete som helhet, har termen "företagshanteringssystem för affärsprocesser" blivit utbredd. Sådana system kännetecknas av användningen av "klient-server"-teknik, inklusive anslutning av fjärranvändare via det globala Internet. Det är inte ovanligt att systemet förenar mer än 40 tusen användare i olika länder och kontinenter till ett gemensamt informationsutrymme. Ett sådant exempel är McDonalds, som har sina divisioner över hela världen, inklusive i Ukraina.
1.5 Problem i samband med datormetoder för informationsbehandling
Helt enkelt att placera anställda på sina arbetsplatser personliga datorer och att ansluta dem till ett lokalt nätverk är osannolikt att ge en positiv effekt i företagsledning, om inte den befintliga informationsstrukturen revideras radikalt. Du kan inte automatisera föråldrade sätt att arbeta, persondatorn kan förvandlas till ett verktyg för höghastighetsproduktion av nya papper. Enligt resultaten av en analys av företagens arbete i USA beskrevs således ett fall då 43 olika dokument upprättades för att inkludera en tillfälligt anställd i ett företags lönelista, totalt 113 sidor, inklusive nödvändiga kopior. Detta sker för att det i informationssystemet finns onödiga kopplingar (kommunikationer) mellan avdelningar och enskilda medarbetare. Samtidigt, för företagets normala funktion, krävs inte mer än 20-30 intern kommunikation, men i själva verket finns det 3-4 gånger fler av dem. Dessutom visar praxis att automatisera företagsledning att installation av produktiv datorutrustning kan leda till en ökning av antalet kommunikationer på grund av utskrift av extra kopior "för säkerhets skull" och deras distribution. Därför bör införandet av datorteknik på företaget föregås av minskningen av onödig kommunikation (anställda) till den optimala nivån.
En av de vanligaste farorna: att tillskriva datorn imaginär kraft. En persondator, oavsett hur dyr och produktiv den är, är bara räknemaskin, som inte kan lösa våra komplexa ekonomiska problem om vi själva inte kan formulera problemet korrekt.
Av stor betydelse är också de sociopsykologiska problem som uppstår i teamet under införandet av datateknik, vilket i regel orsakar en minskning av antalet anställda, förbättring (och därmed förstärkning) av kontrollen över andras verksamhet. anställda osv.
Datorisering förändrar avsevärt tekniken för redovisning och analys av ekonomisk aktivitet. I ett icke-automatiserat redovisningssystem är behandlingen av uppgifter om affärstransaktioner lätt att spåra och åtföljs vanligtvis av dokument på papper - beställningar, instruktioner, konton och redovisningsregister, såsom redovisningsjournaler. Liknande dokument används ofta i ett datorsystem, men i många fall finns de bara i elektronisk form. Dessutom är de viktigaste redovisningsdokumenten (böcker och tidskrifter) i ett datorkontosystem datafiler som inte kan läsas eller ändras utan en dator.
Datorteknik kännetecknas av ett antal egenskaper som bör beaktas vid bedömning av förutsättningar och kontrollförfaranden.
.6 Skillnader mellan datordatabehandling och icke-automatiserad
Enhetligt utförande av operationer. Datorbehandling innebär användning av samma kommandon när man utför identiska redovisningsoperationer, vilket praktiskt taget eliminerar förekomsten av slumpmässiga fel som vanligtvis är inneboende i
manuell bearbetning. Tvärtom leder mjukvarufel (eller andra systematiska fel i hårdvara eller mjukvara) till felaktig behandling av alla identiska operationer under samma förhållanden.
Separering av funktioner. Ett datorsystem kan implementera många interna kontrollprocedurer som inte är det automatiserade system ah utföra olika specialister. Denna situation lämnar yrkesverksamma med tillgång till datorn fria att störa andra funktioner. Som ett resultat av detta kan datorsystem kräva införandet av ytterligare åtgärder för att upprätthålla den kontrollnivå som uppnås i manuella system genom enkel separering av funktioner. Sådana åtgärder kan innefatta ett lösenordssystem som förhindrar åtgärder som är oacceptabla från specialisters sida som har tillgång till information om tillgångar och redovisningsdokument via terminalen i ett onlineläge.
Risk för fel och felaktigheter. Jämfört med manuella redovisningssystem är datorsystem mer öppna för obehörig åtkomst, även av dem som har kontroll. De är också öppna för hemlig ändring av uppgifter och direkt eller indirekt inhämtning av information om tillgångar. Ju mindre mänskligt ingripande i den maskinella bearbetningen av bokföringstransaktioner, desto mindre är möjligheten att upptäcka fel och felaktigheter. Fel som görs i utvecklingen eller korrigeringen av applikationsprogram kan förbli obemärkt under en lång period.
Potentiella möjligheter till ökad kontroll av förvaltningen. Datorsystem förser ledningen med ett brett utbud av analytiska verktyg som gör att de kan utvärdera och kontrollera verksamheten i företaget. Närvaron av ytterligare verktyg säkerställer en förstärkning av det interna kontrollsystemet som helhet och minskar därmed risken för dess ineffektivitet. Så resultaten av den vanliga jämförelsen av de faktiska värdena för kostnadsförhållandet med de planerade, såväl som avstämningen av konton, kommer till administrationen mer regelbundet vid datorbehandling av information. Dessutom samlar vissa applikationsprogram in statistisk information om datorns funktion, som kan användas för att övervaka det faktiska framstegen i behandlingen av bokföringstransaktioner.
Initiera utförandet av operationer på datorn. Ett datorsystem kan utföra vissa operationer automatiskt och deras auktorisering är inte nödvändigtvis dokumenterad, vilket görs i manuella redovisningssystem, eftersom själva det faktum att ett sådant system accepteras av administrationen implicit innebär förekomsten av lämpliga sanktioner.
Således har det sätt på vilket affärstransaktioner behandlas i redovisningen en betydande inverkan på företagets organisationsstruktur, såväl som på procedurerna och metoderna för intern kontroll. En revisors arbete och hans interaktion med förvaltningen förändras kvalitativt. Men automatiseringen av en revisors arbete hämmas av de specifika arbetsförhållandena i ukrainska förhållanden, till exempel ett stort antal dokument som motsäger varandra.
1.7 Teknisk process för informationsbehandling
Det är en ordnad sekvens av åtgärder för att bearbeta data, information, kunskap tills det resultat som krävs av användaren erhålls. Härav följer att begreppet informationsteknologi innebär lösningen av ekonomiska och administrativa problem i samband med utförandet av ett antal operationer för att samla in den information som krävs för att lösa dessa problem, bearbeta den enligt vissa algoritmer och utfärda den till beslutsfattaren i en form som är lämplig för honom.
Den tekniska processen för informationsbehandling beror på arten av de uppgifter som löses, de tekniska medel som används, styrsystem, antalet användare och andra faktorer. Den tekniska processen för informationsbehandling kan innefatta följande operationer (åtgärder):
Insamling av data, information, kunskap - är processen att registrera, fixa, registrera detaljerad information (data, kunskap) om händelser, objekt (verkliga och abstrakta), relationer, tecken och motsvarande handlingar. Samtidigt delas ibland ”data- och informationsinsamling” och ”kunskapsinsamling” upp i separata verksamheter. Insamling av data och information - processen att identifiera och få data från olika källor, gruppera mottagna data och presentera dem i den form som krävs för att komma in i en dator. Kunskapsinsamling - inhämta information om ämnesområdet från specialister - experter och presentera den i den form som krävs för att komma in i kunskapsbasen.
Bearbetning av data, information, kunskap. Bearbetning är ett brett begrepp och omfattar flera inbördes relaterade operationer. Bearbetning inkluderar sådana operationer som: att utföra beräkningar, provtagning, sökning, kombinera, slå samman, sortering, filtrering etc. Man bör komma ihåg att bearbetning är det systematiska utförandet av operationer på data, processen att konvertera beräkningar, analysera och syntetisera alla former av data, information och kunskap, genom att systematiskt utföra operationer på dem. När de definierar en sådan operation som bearbetning skiljer de åt: databehandling, informationsbehandling, kunskapsbearbetning. Databehandling är processen att hantera data (siffror, symboler och bokstäver) och omvandla dem till information. Informationsbehandling - bearbetar information av en viss typ (text, ljud, grafik), omvandlar den till information av en annan typ.
Men användningen av den senaste moderna tekniken ger en omfattande presentation och samtidig bearbetning av information av alla slag (text, grafik, ljud, video, animation), dess transformation. Begreppet kunskapsbearbetning är förknippat med begreppet expertsystem (eller artificiell intelligenssystem), som gör det möjligt, baserat på de regler och fakta som användaren tillhandahåller, att känna igen situationen, ställa en diagnos, formulera ett beslut och ge rekommendationer om val av åtgärder.
Generering av data, information, kunskap - processen för organisation, omorganisation och omvandling av data (information, kunskap) till den form som krävs av användaren, inklusive genom dess bearbetning. Till exempel processen att få formaterade rapporter (dokument).
Lagring av data, information, kunskap - processerna för ackumulering, placering, generering och kopiering av data (information, kunskap) för deras vidare användning (bearbetning och överföring).
Överföring av data, information, kunskap - processen att sprida data (information, kunskap) bland användare genom medel och kommunikationssystem och genom att flytta (sända) data från en källa (avsändare) till en mottagare (mottagare).
2. Utveckling av en minihandledning "Återställa operativsystemet"
2.1 Konvertera text från DJVU till PDF
Hur konverterar man ett dokument från DjVu till PDF? är ett av de vanligaste formaten för elektronisk representation av tryckta dokument, böcker och tidskrifter. Genom att använda Universal Document Conveter kan du lösa problemet med att konvertera ett dokument från DjVu till PDF på ett optimalt sätt.
-
öppnad djvu-fil i Internet Explorer och klickade på knappen Skriv ut i plugin-verktygsfältet.

Ris. 2.1.1 Öppna en fil i Internet Explorer
Valde Universal Document Converter från listan över tillgängliga skrivare och klickade på knappen Egenskaper.

Ris. 2.1.2 Universal Document Converter
I inställningspanelen klickar du på knappen Ladda inställningar.

Ris. 2.1.3 Ladda inställningar
I fönstret Öppna valde jag filen "Textdokument till PDF.xml" och klickade på knappen Öppna.

Ris. 2.1.4 "Texta dokument till PDF.xml"
Klickade på OK-knappen i fönstret Skriv ut för att börja konvertera dokumentet. Den färdiga PDF-filen skapas som standard i mappen My Documents\UDC Output Files.
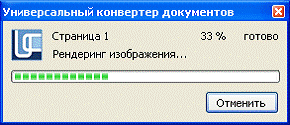
Ris. 2.1.5 dokumentkonvertering
informationsbehandling redigering konvertera
-
Den resulterande kopian av dokumentet kommer att öppnas antingen i programmet Adobe Acrobat, eller i ett annat program som har tilldelats ditt system för att visa PDF-filer.
2.2 PDF till WORD-konvertering
För att kopiera en sida från en PDF-fil till Word-fil, utförde följande steg.
Flyttade till höger sida.
Klickade på knappen Text Select Tool i verktygsfältet Basic Tools.
För att kopiera en hel PDF-fil till ett Word-dokument, följ dessa steg:
Öppnade PDF-filen i Adobe Acrobat Reader.
I menyn Visa valde jag kommandot Kontinuerlig.
Från menyn Redigera valde jag kommandot Välj alla.
Från menyn Redigera väljer du kommandot Kopiera.
Jag bytte till Word och valde Klistra in från menyn Redigera.
Följ dessa steg för att kopiera bilder:
Öppnade PDF-filen i Adobe Acrobat Reader.
Håll ned SHIFT-tangenten och tryck på knappen för textval. Utan att släppa musknappen tryckte jag på knappen Graphic Select Tool på verktygsfältet som dök upp.
När markören tog formen av ett hårkors, ritade du en rektangel runt det önskade mönstret genom att dra markören.
Från menyn Redigera väljer du kommandot Kopiera.
Jag bytte till Word och valde Klistra in från menyn Redigera.
För att avgöra om kopiering av text från ett visst dokument är tillåtet, utför följande steg.
Öppnade PDF-filen i Adobe Acrobat Reader.
Från Arkiv-menyn valde jag kommandona Dokumentinformation och Säkerhet.
När Selecting Text and Graphics är inställt på Tillåtet kan text och grafik i detta dokument kopieras till dokument i andra program.
2.3 Redigera den mottagna texten
- öppnade dokumentfönstret
- Jag valde typsnitt, radavstånd, indrag, kommandot "justify", etc.
-
Som ett resultat fick jag den nödvändiga typen av dokument.

YRKESSÄKERHET OCH HÄLSA
1. Allmänna bestämmelser
1. Personer som genomgått särskild utbildning, läkarundersökning, introduktionsinformation om arbetarskydd, information på arbetsplatsen och genomgång av brandsäkerhet får arbeta på persondator (PC). Omskolning var 6:e månad
2. Användaren måste:
2.1. Följ interna arbetsbestämmelser.
2.3. Följ inte instruktioner som strider mot reglerna för arbetarskydd.
2.4. Kom ihåg personligt ansvar för implementering av arbetarskyddsregler och kollegors säkerhet.
2.5. Kunna ge första hjälpen till olycksoffer.
2.6. Var förtrogen med användningen av primär brandsläckningsutrustning.
2.7. Följ reglerna för personlig hygien.
2.8. Farliga och skadliga produktionsfaktorer som kan påverka användaren:
a) fysisk:
elchock;
ökad nivå av elektromagnetisk och röntgenstrålning;
ökade nivåer av ultraviolett strålning;
ökad ljudnivå på arbetsplatsen från fläktar,
processorer, ljudkort, skrivare;
ökad eller minskad nivå av belysning och reflekterad briljans;
ökad nivå av synförlust;
ojämn fördelning av ljusstyrka i synfältet;
ökad ljusstyrka hos ljusbilden;
ökad nivå av pulsering av ljusflödet;
c) psykofysiologisk:
ansträngning av syn och uppmärksamhet;
intellektuell och emotionell stress;
långa statiska belastningar;
monotoni i arbetet;
en stor mängd information som bearbetas per tidsenhet;
irrationell organisation av arbetsplatsen;
1.3 Rummet med en PC bör ha naturlig och artificiell belysning. Med otillfredsställande belysning minskar PC-användarens produktivitet, närsynthet och trötthet är möjliga (Fig. 3.1).
1.4 Det är inte tillåtet att placera PC-arbetsplatser i källare och källarplan.

Ris. 3.1 - Arbetsplats
6. PC-arbetsstationer under utförandet av kreativt arbete som kräver betydande mental stress eller hög koncentration av uppmärksamhet bör isoleras från varandra med en skiljevägg 1,5-2,0 m hög.
7. Industrilokaler där datorer finns bör inte gränsa till lokaler där buller- och vibrationsnivåer överstiger normen (mekaniska verkstäder, verkstäder etc.).
8. Arbetsplatser med PC rekommenderas placerade i separata rum. Vid placering av arbetsplatser med PC i hallar eller rum med källor till farliga och skadliga faktorer bör de placeras i helt isolerade rum med naturligt ljus och organiserat luftväxling.
9. Området där en arbetsplats med en PC är placerad bör vara minst 6,0 m 2, rummets volym - minst 20 m 3.
10. Golvytan ska vara slät, utan potthål, halkfri, lätt att rengöra och blöt samt ha antistatiska egenskaper.
11. Vid placering av arbetsplatser är det nödvändigt att utesluta möjligheten till direkt belysning av skärmen av en källa av naturligt ljus.
12. Belysningskraven för visuell uppfattning av operatörer av information från två olika medier (PC-skärm och pappersmedia) är olika.
En mycket låg belysningsnivå försämrar uppfattningen av information när du läser dokument, och en mycket hög nivå leder till en minskning av kontrasten i bilden av tecken på skärmen.
Därför bör förhållandet mellan ljusstyrkan på PC-skärmen och ljusstyrkan på de omgivande arbetsytorna i arbetsområdet inte överstiga 3:1, och arbetsytor och omgivande föremål (väggar, utrustning) - 5:1.
13. Artificiell belysning i lokaler med PC bör utföras i form av ett kombinerat belysningssystem med lysrörskällor i allmänbelysningsarmaturer, vilka bör placeras ovanför arbetsytorna på ett enhetligt rektangulärt sätt.
14. För att förhindra att PC-skärmar belyses av direkta ljusflöden måste armaturernas linjer placeras med tillräcklig sidoförskjutning i förhållande till raderna av arbetsplatser eller zoner, och även parallellt med ljushålen. Det är önskvärt att placera fönster på ena sidan av arbetslokalen.
Dessutom ska varje fönster ha ljusspridande gardiner med en reflektionskoefficient på 0,5 -0,7.
15. Konstgjord belysning ska ge en belysning på 300-500 lux på PC-arbetsplatser. Om det är omöjligt att tillhandahålla denna belysningsnivå med ett allmänt belysningssystem är det tillåtet att använda lokala belysningsarmaturer, men det bör inte finnas några reflektioner på skärmytan och en ökning av skärmbelysningen med mer än 300 lux.
16. Vid naturligt ljus bör solskydd tillhandahållas, för detta ändamål kan filmer med metalliserad beläggning eller persienner med vertikalt justerbara lameller användas.
17. Det är nödvändigt att anordna en arbetsplats utrustad med en PC på ett sådant sätt att fönster eller belysningsarmaturer inte faller in i operatörens synfält; de ska inte vara direkt bakom honom.
18. Enhetlig belysning bör säkerställas på arbetsplatsen genom övervägande reflekterad eller diffus ljusfördelning.
19. Ljusreflektioner från tangentbordet, skärmen och andra delar av PC:n i riktning mot operatörens ögon bör inte vara det.
20. För att förhindra bländning bör lokala belysningsarmaturer ha reflektorer gjorda av ogenomskinligt material eller mjölkaktigt glas. Reflektorns skyddsvinkel måste vara minst 40°.
21. PC-arbetsstationer bör placeras på ett avstånd av minst 1,5 m från en vägg med fönsteröppningar, från andra väggar - på ett avstånd av 1 m; med varandra på ett avstånd av minst 1,5 m.
22. Huvudutrustningen på en PC-användares arbetsplats är en bildskärm, tangentbord, skrivbord, stol (fåtölj). Extrautrustning: notställ, fotstöd, skåp, hyllor med mera.
23. När arbetsplatsens delar arrangeras bör följande beaktas:
Användarens arbetsställning.
Utrymme för att rymma användaren.
Möjlighet att se över arbetsplatsens delar.
Förmåga att se utrymmet utanför arbetsplatsen.
Möjlighet att göra anteckningar, lägga upp dokumentation och material som användaren använder (Fig. 3.2).

Ris. 3.2 - Arbetsplats
24. Det ömsesidiga arrangemanget av arbetsplatsens delar bör inte störa genomförandet av alla nödvändiga rörelser och rörelser för driften av PC:n; för att främja det optimala arbetssättet och vila, minska användarens trötthet.
25. För att säkerställa korrekt och snabb läsning av information, bör skärmens yta placeras i den optimala zonen av informationsfältet i ett plan vinkelrätt mot den normala siktlinjen för användaren i arbetsposition. Avvikelse från detta plan är tillåten - inte mer än 45 °; siktlinjens avvikelsevinkel från normalen är tillåten - inte mer än 30 °.
26. Det är nödvändigt att placera PC:n på arbetsplatsen på ett sådant sätt att skärmytan är på optimalt avstånd från användarens ögon, beroende på skärmstorleken.
27. Tangentbordet ska placeras på bordets yta eller på en speciellt höjdjusterbar arbetsyta separat från bordet på ett avstånd av 100-300 mm från kanten närmast arbetskanten, dess lutningsvinkel ska vara inom 5° - 15°.
28. Skrivaren bör placeras så att användaren och hans kollegor kan komma åt den bekvämt; så att det maximala avståndet till skrivarens kontrollknappar inte överstiger längden på en utsträckt arm (höjd 900-1300 mm, djup 400-500 mm).
29. Utformningen av skrivbordet bör ge möjlighet till optimal placering på arbetsytan av den utrustning som används, med hänsyn till dess kvantitet, storlek, designegenskaper (storlek på VDT, tangentbord, skrivare, PC, etc.) och arten av sitt arbete.
30. Höjden på bordets arbetsyta bör regleras inom 680-800 mm; i genomsnitt bör den vara 725 mm.
31. Arbetsytans bredd och djup bör säkerställa möjligheten att utföra arbetsoperationer inom motorfältets gränser, vilka bestäms av zonen inom instrumentens synlighet och kontrollernas räckvidd.
Fördelen bör ges till tabellens modulära dimensioner, på grundval av vilka de strukturella dimensionerna beräknas; bredd bör beaktas: 600, 800, 1000, 1200, 1400 mm; djup - 800, 1000 mm, med sin oreglerade höjd - 725 mm.
32. Bordets yta kan vara matt med liten reflektion och värmeisolerande.
33. Arbetsbordet ska ha ett benutrymme som är minst 600 mm högt, minst 500 mm brett, minst 450 mm djupt i knähöjd och minst 650 mm i höjd med det förlängda benet.
34. Stolen måste säkerställa upprätthållandet av en rationell arbetsställning under utförandet av grundläggande produktionsoperationer, skapa förutsättningar för att ändra arbetsställningen. För att förhindra trötthet bör stolen ge en minskning av statisk spänning i musklerna i nacke-axelområdet och ryggen.
35. Typ av arbetsstol bör väljas beroende på arbetets art och varaktighet. Den ska vara lyft- och vridbar och justerbar i höjd och lutningsvinkel på sits och rygg samt ryggstödets avstånd från sitsens framkant. Regleringen av varje parameter måste vara oberoende och ha en säker fixering. Alla spakar och handtag på enheten (för justering) ska vara lätta att använda.
36. Stolens sits och rygg ska vara halvmjuka, inte elektrifierade och med en lufttät beläggning, vars material möjliggör enkel rengöring från föroreningar.
2 Säkerhetskrav innan arbetet påbörjas
1. Slå på luftkonditioneringssystemet i rummet.
2. Inspektera arbetsplatsen och ordna den; se till att det inte finns några främmande föremål på den; all utrustning och PC-enheter ansluts till systemenheten med anslutningskablar.
3. Kontrollera tillförlitligheten av installationen av utrustning på skrivbordet. VDT ska inte stå på kanten av bordet. Vrid VDT så att det är bekvämt att titta på skärmen - i rät vinkel (och inte från sidan) och något från topp till botten; medan skärmen bör lutas något - dess nedre ände är närmare användaren.
4. Kontrollera utrustningens allmänna skick, kontrollera att de elektriska ledningarna, anslutningskablar, stickproppar, uttag, jordning av skyddsskärmen fungerar.
drift av kablar och ledningar med isolering skadad eller förlorad dess skyddande egenskaper under drift;
lämna kablar och ledningar med nakna ledare spänningssatta;
användningen av hemmagjorda förlängningssladdar som inte uppfyller kraven i de elektriska installationsreglerna för bärbara elektriska ledningar;
användningen av icke-standardiserad (egentillverkad) elektrisk uppvärmningsutrustning eller glödlampor för uppvärmning av rum;
användning av skadade uttag, kopplingsdosor, strömbrytare, såväl som lampor, vars glas har spår av dimning eller utskjutande;
hänga lampor direkt från ledande ledningar, linda elektriska lampor och lampor med papper, tyg och andra brännbara material, använda dem med lock - diffusorer borttagna;
användning av elektrisk utrustning och apparater under förhållanden som inte uppfyller tillverkarens instruktioner (rekommendationer).
6. Justera arbetsplatsens belysning.
7. Justera och fixera stolens höjd, användarvänlig lutning på ryggen.
8. Vid behov, anslut nödvändig utrustning till processorn (skrivare, skanner, etc.). Alla kablar som ansluter systemenheten (processorn) till andra enheter ska endast slås på och av när datorn är avstängd.
9. Slå på datorhårdvaran med strömbrytarna på höljena i sekvensen: spänningsregulator, monitor, processor, skrivare (om utskrift ska vara det).
10. Justera skärmens ljusstyrka, minimistorleken på den lysande punkten, fokus, kontrast. Du bör inte göra bilderna för ljusa, för att inte trötta dina ögon.
skärmens ljusstyrka - inte mindre än 100 cd/m;
förhållandet mellan bildskärmens ljusstyrka och ljusstyrkan på de omgivande ytorna i arbetsområdet - inte mer än 3:1;
minsta glödpunktsstorlek - inte mer än 0,4 mm för en monokrom monitor och inte mindre än 0,6 mm för en färg;
kontrast av bilden av tecknet - inte mindre än 0,8.
11. Om några fel upptäcks, påbörja inte arbetet, informera arbetsledaren om detta.
3.3 Säkerhetskrav under arbete
1. Med videodisplayterminal (VDT):
1.1. Det är nödvändigt att placera tangentbordet stadigt på skrivbordet, vilket förhindrar att det gungar. Det kan dock vara möjligt att rotera och flytta. Tangentbordets position och lutningsvinkeln bör uppfylla användarens önskemål. Om tangentbordsdesignen inte ger utrymme för handflatsstöd, bör de placeras på ett avstånd av minst 100 mm från bordets kant i den optimala zonen av motorfältet. När du arbetar på tangentbordet, sitt rakt, ansträng dig inte.
1.2. För att minska den negativa påverkan på användaren av enheten av "mus"-typ (tvingad hållning, behovet av konstant övervakning av kvaliteten på åtgärder), är det nödvändigt att tillhandahålla en fri stor yta på bordet för att flytta "musen" och en bekväm vila i armbågsleden.
1.3. Främmande samtal, störande ljud är inte tillåtna.
1.4. Med jämna mellanrum, när datorn är avstängd, rengör du damm från utrustningens ytor med en bomullstrasa som knappt är fuktad med tvålvatten. VDT-skärmen och skyddsskärmen torkas av med bomull indränkt i alkohol. Använd inte flytande eller aerosolrengöringsmedel för att rengöra datorytor.
Självständigt reparera utrustning, speciellt VDT. Hårdvarureparationer utförs endast av datorunderhållsspecialister, som måste öppna processorn var sjätte månad och ta bort damm och smuts som har samlats där med en dammsugare.
Att placera föremål på datorns hårdvara, drycker på eller nära tangentbordet kan skada dem.
1.6. För att ta bort statisk elektricitet rekommenderas det då och då att röra metallytorna på de jordade strukturerna i rummet (centralvärmebatteri, etc.).
1.7. För att minska intensiteten i arbetet på en PC är det nödvändigt att jämnt fördela och alternera arbetets karaktär enligt deras komplexitet.
För att minska den negativa effekten av monotoni är det tillrådligt att använda alternerande operationer för att mata in text och numeriska data (ändra innehållet i arbetet), alternerande textredigering och inmatning av data (ändra innehållet och arbetstakten), etc. . (Fig. 3.3).

Ris. 3.3 - Alternerande typ av arbete vid datorn
3.1.8. För att minska den negativa inverkan på hälsan hos arbetare av produktionsfaktorer är det nödvändigt att tillämpa reglerade pauser.
1.9. Belastningen för ett arbetsskift av någon varaktighet bör inte överstiga - 6 timmar.
1.10. Varaktigheten av kontinuerligt arbete för VDT utan reglerad paus bör inte överstiga 2 timmar.
1.11. Lunchrastens längd bestäms av gällande arbetslagstiftning och företagets interna arbetsbestämmelser.
1.12. I händelse av att visuellt obehag eller andra negativa subjektiva förnimmelser uppstår bland dem som arbetar på VDT, bör ett individuellt tillvägagångssätt användas för att begränsa arbetstiden för VDT och korrigera längden på vilopauserna eller ersätta andra typer av arbete (ej relaterat till användningen av VDT).
2. På laserskrivare.
2.1. Placera skrivaren nära processorn så att anslutningssladden inte är under spänning. Placera inte skrivaren på processorn.
2.2. Innan du programmerar skrivarens funktion, se till att den är i kommunikationsläge med en dator.
2.3. För att få de renaste bilderna med högsta upplösning och för att undvika skador på maskinen bör det papper som anges i skrivarens instruktioner användas. Pappersklipp bör göras med ett vasst, gradfritt blad för att minska risken för att papperet skrynklas.
tryckt på ena sidan
för slät och glänsande, samt mycket texturerad;
laminerad;
trasiga, skrynkliga eller med oregelbundna hål från en hålslagare eller häftapparat;
perforerad i flera delar eller cigarett (bas av kolpapper);
från brevhuvuden, vars rubrik är tryckt med icke-värmebeständigt bläck, som måste tåla 200 ° C i 0,1 s; dessa bläck kan överföras till fixeringsvalsen och orsaka utskriftsfel.
3.2.5. Följ reglerna för förvaring av patronen i enlighet med tillverkarens instruktioner (bort från direkt solljus, vid en temperatur på 0 - 35 ° C, etc.).
Det är förbjudet:
- Förvara patronen uppackad.
Sätt patronen på änden, det vill säga vertikalt.
Vänd patronen upp och ner.
Öppna rullskyddet och rör vid det.
Fyll din använda patron själv.
4 Säkerhetskrav efter avslutat arbete
1. Avsluta och skriv till datorns minne filen som du arbetar med. Avsluta programskalet och återgå till MS DOS-miljön.
2. Stäng av skrivaren, annan kringutrustning, stäng av VDT och processorn. Stäng av stabilisatorn om datorn är ansluten till nätverket via den. Dra ut kontakterna ur uttagen. Täck tangentbordet med ett lock för att förhindra att damm kommer in i det.
3. Städa upp arbetsplatsen. Lägg original och andra dokument i en skrivbordslåda.
4. Tvätta händerna noggrant med varmt vatten och tvål.
5. Stäng av luftkonditioneringen, belysningen och den allmänna strömförsörjningen till enheten.
5 Säkerhetskrav i nödsituationer
5.1.2. Kommandot "Stopp!" som ges av alla anställda måste följas av alla som hört det.
5.1.3. I händelse av en elektrisk stöt på en arbetare, släpp offret från inverkan av elektrisk ström:
v stäng av strömförsörjningen från detta område;
v separera offret från spänningsförande delar med hjälp av dielektriska handskar, annan skyddsutrustning eller isolerande saker eller föremål;
v ringa en läkare och före hans ankomst ge offret första hjälpen;
v Rapportera händelsen till din linjechef.
5.1.4. Om en kortslutning uppstår i strömförsörjningsnätet, avbryt omedelbart arbetet och koppla bort det skadade strömförsörjningsnätet. Rapportera till sektionschefen. Det är FÖRBJUDET att eliminera kortslutningen själv!
5.1.5. I händelse av ett strömavbrott, koppla bort datorn från nätverket, rapportera till chefen för webbplatsen.
5.1.6. Om nätsladdarna börjar brinna, avbryt omedelbart arbetet, stäng av strömförsörjningen till PC:n och börja släcka elden med en kolsyrebrandsläckare, vid behov ring brandkåren - tel. 01. Rapportera till chefen för sajten.
5.1.7. I händelse av hot om en nödsituation är den anställde skyldig att vidta alla möjliga åtgärder för att förhindra det, ge första hjälpen till offret, informera sin närmaste chef och vid behov ringa ambulans.
5.1.8. I händelse av en olycka, om möjligt (om det inte hotar andra anställdas liv och hälsa och inte leder till allvarligare konsekvenser), är det nödvändigt att hålla utrustningen och miljön på arbetsplatsen i samma skick som det var vid tiden för händelsen.
1.9. När man eliminerar konsekvenserna av en olycka eller naturkatastrof är genomförandet av säkerhetsregler för alla kategorier av arbetstagare obligatoriskt.
1.10. Anställda som har begått brott mot kraven i denna instruktion är ansvariga i enlighet med det förfarande som fastställts i lag.
Slutsats
Under loppet av detta examensarbete uppnådde jag det ursprungligen uppsatta målet, nämligen att jag grundligt studerade informationstyperna, utforskade och beskrev metoderna och teknologierna för att bearbeta olika typer av information. Under loppet av att skriva min avhandling kom jag till slutsatsen att med tillkomsten av datorer (eller, som de först kallades i vårt land, datorer - elektroniska datorer), uppstod ett sätt att bearbeta numerisk information först. Men i framtiden, särskilt efter den utbredda användningen av persondatorer (PC), började datorer användas för att lagra, bearbeta, sända och söka efter text-, numerisk, visuell, ljud- och videoinformation. Sedan tillkomsten av de första persondatorerna - PC (80-talet av 1900-talet) - ägnas upp till 80 % av deras arbetstid åt att arbeta med textinformation.
När man analyserar den mottagna informationen bör det noteras: behandlingen av information (reproduktion, konvertering, överföring, inspelning till externa media) utförs av datorprocessorn. Med hjälp av en dator är det möjligt att skapa och lagra ny information av alla slag, för vilka speciella program som används på datorer och informationsinmatningsenheter tjänar.
För närvarande kan information som presenteras på det globala Internet betraktas som en speciell typ av information. Den använder speciella tekniker för att lagra, bearbeta, söka och överföra distribuerad information av stora volymer och speciella sätt att arbeta med olika typer av information. Mjukvaran som ger kollektivt arbete med information av alla slag förbättras ständigt.
Bibliografi
1. Informationssystem. Wikipedia gratis uppslagsverk [elektronisk resurs]
2. Filserver. Wikipedia gratis uppslagsverk [elektronisk resurs]
Shokin Yu.I., Fedotov A.M. Distribuerade informationssystem [Elektronisk resurs]
L.F. Kulikovsky, V.V. Motov "Teoretiska grunder för informationsprocesser: Proc. ersättning för universitet. - K. 2009
V. Dmitriev "Tillämpad informationsteori". - M., 2008
A.G. Kushnirenko, G.V. Lebedev, R.A. Svin. "Grunderna i datavetenskap och datateknik." Kiev "ENLIGHTENMENT" 2008
Dokuchaev A.A., Moshensky S.A., Nazarov O.V. Informatikverktyg på ett handelsföretags kontor. Medel för datorkommunikation. - St Petersburg: TEI, 2010, 32 sid.
Datorteknik för informationsbehandling. // Ed. Nazarova S.I. - M.: Finans och statistik, 2008.
Nans B. Datornätverk. - M .: Eastern Book Company, 1996.
Friedland A. Informatik - en förklarande ordbok över grundläggande termer. - M.: Prior, 1998.
Shatt S. Världen av datornätverk. - Kiev: BHV, 2006
Shafrin Y. Informationsteknik. - M., 2010
Teknik för behandling av informationsdata
IT används i stor utsträckning inom olika verksamhetsområden i det moderna samhället och, först och främst, inom informationssfär De gör det möjligt att optimera olika IP:er, från utarbetande och publicering av tryckt material till informationsmodellering och prognostisering av globala utvecklingsprocesser i naturen och samhället. Samtidigt används IT inom alla ämnesområden oftast för data(informations)behandling.
Bearbetning är ett brett begrepp, ofta med flera sammanlänkade mindre verksamheter. Bearbetning inkluderar operationerna att utföra beräkningar, provtagning, sökning, kombinera, sammanfoga, sortering, filtrering, etc.
Det är viktigt att komma ihåg det behandling - det är det systematiska utförandet av operationer på data (information, kunskap); processen för omvandling, beräkning, analys och syntes av alla former av data, information och kunskap genom att systematiskt utföra operationer på dem.
Vanligtvis utpekas operationerna för att behandla data, information och kunskap separat.
Informationstekniken beror på arten av de uppgifter som löses, vilken datateknik som används, antalet användare, systemen för att övervaka etc. Samtidigt används den för att lösa välstrukturerade problem med tillgängliga indata och algoritmer, samt standardprocedurer för deras bearbetning. .
Den tekniska processen för informationsbehandling kan innefatta följande operationer (åtgärder): generering, insamling, registrering, analys, faktisk bearbetning, ackumulering, sökning efter data, information, kunskap, etc.
Informationsbehandling sker i processen att implementera den tekniska process som bestäms av ämnesområdet. Överväga de viktigaste operationerna (åtgärderna) i den tekniska processen för informationsbehandling.
1) Insamling av data, information, kunskap. Denna operation är en process för att registrera, fixa, registrera detaljerad information (data, kunskap) om händelser, objekt (verkliga och abstrakta), relationer, egenskaper och motsvarande handlingar. Samtidigt särskiljs ibland ”data- och informationsinsamling” och ”kunskapsinsamling” i separata verksamheter.
Att samla kunskap– det handlar om att inhämta information om ämnesområdet från specialister (experter) och presentera den i den form som behövs för registrering i kunskapsbasen.
Det finns mekaniserade, automatiserade och automatiska metoder för att samla in och registrera information och data. Alternativ automatisk informationsinsamlingsteknikär RFID (från engelskan radio frequency identification - radio frequency identification) - ett speciellt mikrochip på några centimeters storlek, inbäddat i ett föremål. Med hjälp av RFID-antennen som finns i den ger den utbyte av information med externa enheter(dator etc.). Den låter dig diagnostisera utrustning, identifiera komponenter som behöver bytas ut, etc. Införandet av denna teknik kommer att tillhandahålla högeffektiva metoder för redovisning och service av olika produkter och objekt.
2) Bearbetning av data, information, kunskap. Bearbetningen innefattar ofta flera sammanlänkade mindre operationer. Bearbetning inkluderar sådana operationer som: utföra beräkningar, provtagning, sökning, kombinera, sammanfoga, sortering, filtrering, etc. Bearbetning är ett systematiskt utförande av operationer på data, processen att konvertera, beräkna , analys och syntes av alla former av data, information och kunskap genom att systematiskt utföra operationer på dem.
När en sådan operation definieras som bearbetning särskiljs begreppen "databehandling", "informationsbehandling" och "kunskapsbehandling". Samtidigt uppmärksammas bearbetningen av text, grafisk, multimedia och annan information.
Ordbehandlingär ett av e-kontorsverktygen.
Vanligtvis är den mest tidskrävande processen att arbeta med elektronisk text dess inmatning i en dator. Den följs av stadierna för förberedelse (inklusive redigering) av texten, dess design, sparande och utmatning. Denna typ av bearbetning ger användarna olika verktyg som ökar effektiviteten och produktiviteten i deras aktiviteter. Samtidigt finns det program som känner igen scannad text, vilket i hög grad underlättar arbetet med sådan data.
Bildbehandling har blivit utbredd med utvecklingen av elektronisk utrustning och teknik. Bildbehandling kräver höga hastigheter, stora mängder minne, specialiserad hårdvara och mjukvara. Samtidigt finns det sätt att skanna bilder som i hög grad underlättar deras inmatning och bearbetning i en dator. Datorteknik använder vektor-, raster- och fraktalgrafik. Bilder har ett annat utseende, kan vara två- och tredimensionella, med markerade konturer osv.
Tabellbearbetning utförs av speciella applikationsprogram, kompletterade med makron, diagram, analytiska och andra funktioner. Att arbeta med ett kalkylblad låter dig ange och uppdatera data, kommandon, formler, bestämma relationen och ömsesidigt beroende mellan celler (celler), tabeller, sidor, filer med tabeller och databaser, data i form av funktioner vars argument är poster i celler.
Databehandling kan utföras i interaktiva lägen och i bakgrundslägen. Denna teknik utvecklades huvudsakligen i DBMS.
Följande metoder för databehandling är välkända: centraliserad, decentraliserad, distribuerad och integrerad.
Centraliserad databehandling i datorn var främst en batchbearbetning av information. Samtidigt levererade användaren sin initiala information till datorcentralen (nedan - CC), och fick sedan bearbetningsresultaten i form av dokument och (eller) media. Ett kännetecken för denna metod är komplexiteten och mödan i att etablera snabbt, oavbrutet arbete, en stor arbetsbelastning av CC-information (stor volym), reglering av drifttiden, organisation av systemsäkerhet från eventuell obehörig åtkomst. Eftersom komplexiteten hos de uppgifter som löses vanligtvis är omvänt proportionell mot deras antal, ledde centraliserad databehandling ofta till ineffektiv användning av den centrala datorns beräkningsresurser, begränsad användaråtkomst till dess resurser, men krävde betydande materialkostnader för skapande och drift av databehandlingssystem.
Principen om centraliserad databehandling uppfyllde tidigare inte höga krav på bearbetningsprocessens tillförlitlighet, hindrade utvecklingen av system och kunde inte tillhandahålla nödvändiga tidsparametrar för onlinedatabehandling i fleranvändarläge. Och även ett kortvarigt fel på den centrala datorn kan leda till allvarliga negativa konsekvenser. Nu har denna teknik fått en ny utveckling i de mycket tillförlitliga och effektiva databehandlingscenter som skapas (nedan kallat DPC).
Decentraliserad databehandling i samband med uppkomsten av persondatorer (små datorer, mikrodatorer), vilket gjorde det möjligt att automatisera specifika jobb och ledde till uppkomsten av distribuerad databehandling.
Distribuerad databehandling- detta är databehandling som utförs på oberoende, men sammankopplade datorer, som representerar ett distribuerat system, det vill säga i datorinformationsnätverk. Det genomförs på två sätt. Den första innebär installation av en dator i varje nätverksnod (eller på varje nivå i systemet), medan databehandling utförs av en eller flera datorer, beroende på systemets verkliga kapacitet och dess behov vid den aktuella tidpunkten.
Det andra sättet involverar placeringen av ett stort antal olika processorer inom ett enda system. Den distribuerade metoden är baserad på ett komplex av specialiserade processorer - varje dator används för att lösa vissa uppgifter, eller uppgifter på sin egen nivå. Det används där ett databearbetningsnätverk behövs (filialer, avdelningar etc.), till exempel i bank- och finansiell informationsbehandlingssystem.
Fördelarna med denna metod ligger i möjligheten: att behandla vilken mängd data som helst med en hög grad av tillförlitlighet inom en given tidsram (om ett tekniskt medel misslyckas kan du omedelbart ersätta det med ett annat); minska tid och kostnader för dataöverföring; öka systemens flexibilitet; förenkla utveckling och drift av mjukvara m.m.
Ett integrerat sätt att bearbeta information tillhandahåller skapandet av en informationsmodell för ett hanterat objekt - RDB. Det ger maximal användarvänlighet. Å ena sidan tillhandahåller databaser kollektiv användning och centraliserad hantering. Å andra sidan kräver mängden information, mångfalden av uppgifter som ska lösas distribution av databasen. Tekniken för integrerad informationsbehandling gör det möjligt att förbättra kvaliteten, tillförlitligheten och hastigheten för behandlingen, eftersom behandlingen utförs på basis av en enda informationsmatris, när den väl har matats in i datorn.
Det speciella med denna metod ligger i den tekniska och tidsmässiga separationen av bearbetningsförfarandet från förfarandena för insamling, förberedelse och inmatning av data.
I informationsnätverk utförs informationsbearbetning på olika sätt: i batch- och schemalagda lägen; realtids-, tidsdelnings- och telebearbetningslägen, såväl som i fråga, dialog, interaktiva; enkelprograms- och flerprogramslägen (multi-processing).
Databehandling i batch-läge innebär att varje del av icke-brådskande överförd information (som regel i stora volymer) behandlas utan inblandning utifrån - bildandet av rapporteringsdata (sammanfattningar, etc.). När du använder den har användaren inte direkt kommunikation med datorn. Det rör sig i regel om uppgifter av icke-operativ karaktär, med en långsiktig giltighet av lösningens resultat. Samtidigt sammanfaller inte insamling, registrering, inmatning och bearbetning av information i tid. Först samlar användaren information och formar den till paket i enlighet med typen av uppgifter eller andra egenskaper. Efter att ha mottagit informationen läggs den in och bearbetas. Resultatet är en bearbetningsfördröjning.
Detta läge kallas ibland för bakgrundsläge. Det implementeras när datorsystemens resurser är lediga och bearbetningen kan avbrytas av mer brådskande och prioriterade processer och meddelanden, varefter den återupptas automatiskt. Läget används som regel med en centraliserad metod för informationsbehandling.
I tidsdelningsläge i en dator växlar processerna för att lösa olika problem i tiden. I detta läge tillhandahålls datorresurserna (system)resurserna för optimal användning omedelbart till en grupp användare cykliskt, under korta tidsintervall. I det här fallet allokerar systemet sina resurser till en grupp användare i tur och ordning. Eftersom datorn snabbt betjänar var och en av användargruppen, ger den intrycket av deras samtidiga arbete. Denna möjlighet uppnås genom att använda speciell programvara.
Realtidsläge - det är en teknik. tillhandahålla svar från anläggningsledningen som motsvarar dynamiken i dess produktionsprocesser. Det betyder förmågan hos ett datorsystem att interagera med kontrollerade eller kontrollerade processer i takt med dessa processer. Reaktionstiden kan mätas i sekunder, minuter, timmar och bör passa takten i den kontrollerade processen eller användarnas krav och ha en minimal fördröjning.
I realtidssystem slutförs databehandlingen för ett meddelande (begäran) innan ett annat visas. Som regel används detta läge för decentraliserad och distribuerad databehandling och används för objekt med dynamiska processer. Till exempel måste kundtjänst i en bank för alla tjänster ta hänsyn till den tillåtna väntetiden för en kund, den samtidiga servicen av flera kunder och passa in i specificerat intervall tid (systemets reaktionstid).
interaktivt läge innebär möjligheten till tvåvägsinteraktion mellan användaren och systemet, dvs användaren kan påverka databehandlingsprocessen. Interaktivt arbete utförs i realtid och används vanligtvis för att organisera en dialog (dialogläge).
Dialogläge (fråga). Det kännetecknas av användarens förmåga att direkt interagera med datorn medan han arbetar med den. Databehandlingsprogram kan finnas i datorns minne permanent (datorn är tillgänglig när som helst) eller under en viss tid (endast när datorn är tillgänglig för användaren).
Dialoginteraktion mellan en användare och en dator kan vara mångfacetterad och bestäms av sådana faktorer som: kommunikationsspråket; aktiv eller passiv användarroll; vem som är initiativtagare till dialogen (användare eller dator); respons tid; dialogens struktur etc. Om initiativtagaren till dialogen är användaren måste han ha kunskaper och färdigheter i att arbeta med procedurer, dataformat etc. Om initiativtagaren är en dator så står det vid varje steg vad som användaren måste göra - menyvalsmetod. Denna metod ger stöd för användaråtgärder och föreskriver deras sekvens. I det här fallet krävs mindre utbildning av användaren.
Det interaktiva läget kräver en viss nivå av teknisk utrustning för användaren: närvaron av en terminal eller PC ansluten via telekommunikation till den centrala datorn. Möjligheten att arbeta i ett interaktivt läge kan vara tidsbegränsad i början och slutet av arbetet, eller så kan den vara obegränsad. Läget används för att komma åt information, datorer eller mjukvaruresurser.
Ibland görs en skillnad mellan interaktiva och frågelägen. Under begäran läge förstås som en engångsåtkomst till systemet, varefter det utfärdar ett svar och stängs av (till exempel ett hjälpsystem), och under interaktiv– ett läge där systemet, efter en begäran, utfärdar och väntar på ytterligare användaråtgärder.
Telebearbetningsläge tillåter en fjärranvändare att interagera med en dator (det kallas ibland en terminal).
Enkelt program eller multiprogramlägen karakterisera systemets förmåga att arbeta samtidigt på ett eller flera program.
Regleringssystemär fokuserad på en tidsdefinierad sekvens av att utföra individuella användaruppgifter. Till exempel regelbunden (månatlig, kvartalsvis, etc.) mottagning av resultatsammanställningar och rapporter, beräkning av löneutdrag för vissa datum etc. Samtidigt urskiljs regelbundna, särskilda, jämförande, akuta och andra typer av rapporter. Regelbundna rapporter skapas vanligtvis på begäran av förvaltningen eller vid oplanerade situationer. Dessa rapporter kan ha formen av sammanfattande, jämförande och extraordinära rapporter. PÅ sammanfattande rapporter data kombineras i separata grupper, sorteras, presenteras i form av mellan- och slutsummor för enskilda fält. Jämförande rapporter inkludera data som erhållits från olika källor eller kvalificerats enligt olika kriterier och används för jämförelseändamål. Nödrapporter innehålla uppgifter av exceptionell (extraordinär) karaktär.
Databehandling innebär behandling av information av en viss typ (text, ljud, grafik, etc.) och dess omvandling till information av en annan specifik typ. Så, till exempel, är det vanligt att skilja mellan bearbetning av textinformation, bilder (grafik, foton, videor och animationer) och ljudinformation (tal, musik, etc.). ljudsignaler). Användningen av den senaste tekniken säkerställer deras heltäckande presentation. Samtidigt kan mänskligt tänkande betraktas som en process för informationsbehandling.
Informationsbehandling IT är utformad för att lösa välstrukturerade uppgifter för vilka nödvändiga indata finns tillgängliga, algoritmer och andra standardprocedurer för deras bearbetning är kända. Denna teknik används för att automatisera rutinmässiga, ständigt återkommande operationer, vilket gör det möjligt att öka arbetsproduktiviteten, befria utförare från rutinarbete och ibland minska antalet anställda. Samtidigt löses följande uppgifter: databehandling; generera periodiska statusrapporter; gällde att få svar på olika aktuella förfrågningar och behandla dessa i form av handlingar och rapporter. När du ansöker. IT såsom: insamling och registrering av data direkt i produktionsprocessen i form av ett dokument med hjälp av en central dator eller persondatorer; databehandling i dialogläge; aggregering (kombination) av data; användning av elektroniska medier (till exempel diskar).
Den tekniska processen för informationsbehandling med hjälp av en dator inkluderar följande operationer:
1) Mottagande och anskaffning av primära dokument (kontroll av fullständigheten och kvaliteten på deras ifyllning, fullständighet, etc.);
2) Förberedelse av elektroniska medier och kontroll av dess tillstånd;
3) Mata in data i en dator;
4) Kontroll, vars resultat matas ut till externa enheter (skrivare, bildskärm, etc.).
Det finns andra liknande tekniker, men låt oss vara uppmärksamma på IT (drift) datakontroll, sällan beaktas i specialpedagogisk litteratur. I olika situationer är det nödvändigt att kontrollera mottagen eller distribuerad data och information. För detta ändamål används IT flitigt. Skilj mellan visuell kontroll och programkontroll, vilket gör att du kan spåra information för fullständig inmatning, kränkning av strukturen för källdata, kodningsfel. Kontroll är inte ett självändamål. När ett fel hittas:
Korrigering av indata, korrigering och återinmatning;
Spela in ingångsinformation i de ursprungliga arrayerna;
sortering (om nödvändigt);
databehandling;
· upprepad kontroll och utfärdande av slutlig information.
Låt oss överväga mer detaljerat behandlingen av de olika typerna (typerna) av information som nämns ovan.
En fil är en uppsättning logiskt relaterade data i en form som är bekväm för lagring och bearbetning av ett datorsystem. En fil är en samling logiska poster.
När man talar om de poster som utgör en fil, utelämnas ofta ordet "logisk". Varje filpost innehåller data som har ett specifikt syfte. I filer som används för inventeringsändamål kan varje post representera en samling data relaterade till en produktartikel. I en skolhanterad studentpostfil kan posten innehålla elevens namn, kontonummer, kursnummer och provresultat. Bankbokföring kan till exempel innehålla uppgifter som kundnummer, namn, löpande konto och uppgifter om transaktioner som utförts av honom under den senaste månaden. Anteckningar i IRS-filerna kan bestå av belopp som debiteras vissa skattebetalare under innevarande år. Nuförtiden är många programmeringsuppgifter relaterade till organisation och hantering av filer.
En betydande del av operativsystemet är utformat för att göra det lättare för användaren att hantera och bearbeta data. Men operativsystemet måste också hantera mycket annan information. Detta inkluderar källkod i maskinspråk, bibliotek med subrutiner, indata för körande jobb och deras utdata. Data för bearbetning av operativsystemet kan representeras som datamängder. En datauppsättning är den största samlingen av information som systemet arbetar på och är en uppsättning data som representeras i minnet på något speciellt sätt, tillsammans med ytterligare kontrollinformation som ger tillgång till ett godtyckligt element i denna uppsättning. Varje operativsystem fungerar med uppsättningar som har en av flera giltiga strukturer.
För att hantera sina egna filer använder användarna vanligtvis funktionerna i operativsystemet. Typen av struktur som används avgör hur själva datasetet är organiserat. Vi ska kort beskriva hur datamängder är organiserade, men först ska vi titta närmare på förhållandet mellan individuella logiska filposter och I/O-operationer.
Blockera och registrera
Som redan nämnts består filer av en eller flera logiska poster. Posten kan vara en strängutmatning till utskriftsenheten eller innehållet på ett hålkort. Om vi pratar om ett assemblerspråksprogram, så är posten här en mening av källspråket, som har en längd på 80 byte. En filpost som innehåller information om en viss elev kan vara 500 byte lång. Generellt sett bestäms längden på posterna, liksom innehållet, av syftet med filen.
En fysisk post, eller block, är information som överförs av en in- eller utenhet i en enda operation. För en hålkortsläsare eller utgångsstansare består blocket av 80 byte, eftersom exakt 80 byte kodas av ett hålkort. Utskriftsenhetsblocket är vanligtvis en sträng på 132 byte. I sådana anordningar, dvs anordningar där blockstorlekarna strikt bestäms av själva hårdvaran, kan antalet logiska poster i blocket inte ändras, och det finns alltid exakt en post per block. Sådana anordningar kallas engångsanordningar. På andra enheter, såsom magnetskivor och tejp, till exempel, är blockstorlekarna inte strikt definierade. I dessa fall väljs de av programmerarna själva. Fysiska poster är inte nödvändigtvis lika stora som logiska poster. Formatet för poster i en datauppsättning ges av förhållandet mellan storlekarna på motsvarande poster och block.
Ris. 17.1. Spela in format.
I de fall där fysiska och logiska poster är av samma storlek, sägs posterna vara olåsta. Blockerade dataformat talas om när det finns mer än en logisk post per fysisk post. Det kan också finnas ett fall där storleken på enskilda poster överstiger storleken på block. Skivor i en sådan uppsättning kallas transitional.
Blockstorleken i en datamängd är inte nödvändigtvis ett konstant värde. I det här fallet talar vi om block med variabel längd, och värdena för de kvantiteter som kännetecknar storleken på blocken skrivs inuti själva blocken. Om alla block i uppsättningen är lika stora talar vi om en datamängd med block med fast längd.
I praktiken finns det en mängd olika kombinationer av blockstorlekar och enskilda poster. Några möjliga fall visas i fig. 17.1. Datauppsättningen som visas i fig. 17.1, men kan till exempel motsvara en hålkortsfil. Längden på varje block är 80 byte, var och en av dem har exakt en logisk post. Den uppsättning som visas i fig. 17.1.6 består av 100-byte-poster. Blocken i denna uppsättning är 300 byte långa. Detta betyder att i processen för inmatning eller utmatning av data från denna uppsättning, inom en operation, kommer information att matas in respektive ut, vilket är 300 byte. När uppsättningen bearbetas av användarprogrammet eller operativsystemsprogrammen kommer blocken att delas upp i separata poster. På fig. 17.1c visar en datamängd med rullande poster av konstant längd. Inmatning eller utmatning av en godtycklig post involverar två I/O-operationer. Datauppsättning fig. 17.1, d är sammansatt av poster med variabel längd. Dessutom är variablerna i detta fall både längden på ett separat block och antalet poster i det. Uppgiften att dela upp varje block i poster tilldelas återigen bearbetningsprogrammet.
Sätt att organisera datauppsättningar
Efter att ha bekantat oss med de olika möjligheterna att dela upp datamängder i beståndsdelar - block och poster - övergår vi nu till övervägandet av frågor relaterade till uppsättningens allmänna struktur. Organisationen av en uppsättning förstås som det ömsesidiga arrangemanget av dess ingående block och de relationer som förbinder vart och ett av blocken och datamängden som helhet. Valet av ett visst sätt att organisera en uppsättning beror på flera faktorer. Detta inkluderar vilken typ av enhet på vilken uppsättningen lagras och i vilken ordning de enskilda posterna läses, och slutligen för vilket syfte uppsättningen skapas.
Konsekvent organisation. Vissa kringutrustningar, såsom bandenheter eller enheter för enstaka inspelningar, definierar unikt hur en given uppsättning data är organiserad. Poster i detta fall behandlas exakt i den ordning som de lagras. Hålkortsläsaren matar in det ursprungliga arraykortet för kort i exakt den ordning som den är förberedd för inmatning. Utskriftsenheten skriver ut rad för rad i den ordning de kommer till den. Den inkommande informationen registreras på magnetbandet i form av block, även den i mottagningsordning. Efterföljande inmatning från bandet kommer att vara i den ordning som blocken placeras på den.

Ris. 17.2. Fil med sekventiell organisation.
Å andra sidan gör direktåtkomstanordningar, såsom till exempel magnetiska skivenheter, det möjligt att skriva och läsa block placerade på en godtycklig plats. För att göra detta behöver du bara ange postens adress. Med andra ord kan bearbetningen av posterna i uppsättningen ske i en godtycklig ordning, givetvis förutsatt att vi känner till adresserna till deras placering eller adresserna som de ska placeras på. Men i de flesta applikationer är den fysiska ordningen för posterna i en uppsättning den ordning i vilken du vill bearbeta dem. Det är ytterst sällsynt att de enskilda bidragen som utgör originalprogrammets meningar behöver granskas i en annan ordning än den ordning de är skrivna i. Detsamma kan sägas för objekt- och lastmoduler skrivna i maskinspråk.
Filer där behandlingen av enskilda poster sker i den ordning de är fysiskt placerade kallas sekventiell. När man skapar en sekventiell fil eller lägger till nya poster till den, sammanfaller den ordning i vilken informationen registreras med den ordning i vilken den anländer till kringutrustningen. Att läsa posterna för en sekventiell fil sker i den ordning de är placerade i den. Behandlingen av information i den ordning den placeras på enheten eller i minnet kallas sekventiell bearbetning.
Sekventiella filer lagras i sekventiellt organiserade datamängder. På fig. 17.2 är ett exempel på en sekventiellt organiserad datamängd. Det sista blocket i uppsättningen följs av ett speciellt block, kallat ett bandmärke, vilket är ett tecken på slutet av datamängden. När nästa block läggs till i den sekventiella uppsättningen, överlappas bandmärket av detta block och ett nytt märke skrivs omedelbart efter det. Vid inmatning av en datamängd läses posterna i exakt den ordning som de är skrivna i uppsättningen, inmatningen sker tills ett bandmärke påträffas.
biblioteksorganisation. Vi har redan nämnt att det finns några systembibliotek som är av stor betydelse för användarna. Detta inkluderar systemmakrobiblioteket, biblioteket med katalogiserade procedurer, biblioteken systemprogram och testfall. Varje sektion av biblioteket är en sekventiell uppsättning data. Till exempel innehåller OS-systemets katalogiserade procedurbibliotek sektioner som ASMFCLG, FORTGCLG och COBUCG.
Bibliotekets innehåll efterfrågas med sektionsnamn. Till exempel, när man bearbetar INITIAL-makroinstruktionen, frågar assemblern avsnittet med namnet INITIAL som finns i systemets makrobibliotek. En datamängd som består av en eller flera sektioner och som är organiserad på ett sådant sätt att åtkomsten till dess individuella sektioner sker genom deras namn kallas en biblioteksmängd.

Ris. 17.3. Strukturen för bibliotekets datauppsättning som innehåller de speciella makron som används i den här boken.
Biblioteksdatauppsättningar lagras på enheter med direktåtkomst. Detta gör att du kan fråga enskilda sektioner och endast ange adresserna för deras början. För att underlätta sökningen efter en sektion av biblioteket skapar systemet en speciell tabell som kallas innehållsförteckningen, där namnet på varje sektion av datamängden motsvarar adressen till dess början. På fig. 17.3 är ett exempel på strukturen för en biblioteksuppsättning. Om en viss del av biblioteket efterfrågas, söker systemet i innehållsförteckningen efter motsvarande namn. Adressen associerad med det angivna namnet bestäms sedan och används direkt för att lokalisera den sekventiella datamängden som representerar den erforderliga sektionen.
Operativsystemet tillhandahåller användaren specialprogram att skapa och underhålla dina egna biblioteksuppsättningar. OS använder också biblioteksdatauppsättningar för att underhålla sina egna bibliotek. Att arbeta med bibliotek i DOS-systemet skiljer sig inte mycket från det som tillhandahålls i operativsystemet, men DOS innehåller inga speciella verktyg som tillåter användare att skapa sina egna biblioteksuppsättningar och utföra underhållsarbete på dem.
Index-sekventiell organisation. I vissa applikationer kan det vara mycket bekvämt att använda både sekventiell bearbetning av en uppsättning, att välja enskilda poster i den ordning som de lagras i någon enhet, och godtycklig bearbetning utan hänsyn till platsen för enskilda poster, läsa, lägga till och ändra poster. Återkalla vårt bearbetningsprogram Vi var tvungna att lagra i minnet en post motsvarande varje tillgänglig post, en post för varje post. nyckelvärden I slutet av varje vecka utfärdades en rapport om filens status vid den aktuella moment.Rapporten bestod av poster i sekventiell ordning. Eftersom posterna i filen sorterades efter stigande nycklar var ordningen på posterna i rapporten naturligtvis densamma, vilket gjorde det lättare att söka i den en sträng som motsvarar ett visst namn ania.
Under veckan kunde dock situationen förändras: företaget kunde producera eller köpa helt nya produkter, gamla produkter kunde successivt säljas. Allt detta kräver ändringar i bokföringsfilen. För att kunna göra en ändring i en post måste den först hittas. För att hitta en post kan du ordna att titta igenom hela filen från början tills den önskade posten hittas. Men om filen redan innehåller flera tusen poster kan en sådan uppslagning varje gång en ändring krävs av någon post vara för slösaktig i termer av maskintid.

Ris. 17.4. Filstruktur med indexsekventiell organisation.
Faktum är att vi behöver ett sätt att organisera en datamängd där åtkomst till enskilda poster i den kan göras både sekventiellt och med hjälp av nycklar.
Detta sätt att organisera data är indexsekventiell organisation. När du skapar en indexsekventiell datauppsättning sorteras först filposterna efter nycklar. I vårt kontohanteringsexempel kommer motsvarande kontonummer att användas som registreringsnyckel. Posterna matas sedan ut sekventiellt. De placeras av systemet på direktåtkomstenheten. Detta bygger ett eller flera index. Om det är lämpligt kan bearbetningen av uppsättningen som skapats på detta sätt utföras sekventiellt i den ordning i vilken posterna kommer till motsvarande anordning. Å andra sidan kan varje specifik post också frågas efter nyckel, med hjälp av index som byggts av systemet för att påskynda sökningen efter den önskade posten.
På fig. 17.4 visar ett exempel på en enkelindexorganisation av en datamängd. Källfilen är uppdelad i underfiler, som var och en motsvarar en viss rad i indextabellen. Denna rad innehåller information om nyckeln till den sista och adressen till den första posten i underfilen. Om en fråga inträffar för en post med något givet nyckelvärde, skannar systemet först av indextabellen och letar efter den första raden som innehåller ett värde som är större än eller lika med det givna värdet. Den obligatoriska posten tillhör underfilen som motsvarar denna rad, så ytterligare sökningar görs endast bland elementen i denna underfil.
Systemet har möjlighet att lägga till nya poster på lämplig plats i filen och ta bort gamla poster. Den indexsekventiella organisationen utökar således möjligheterna för filbehandling avsevärt. Poster kan behandlas antingen sekventiellt eller slumpmässigt. Allt detta förutsätter dock ordningen av posterna i källfilen.
direkt organisation. Om de direkta adresserna till vilka de enskilda posterna i filen placeras är satta av användaren själv, så talar man om en direkt organisation av datamängden. Vanligtvis används nycklarna för att bestämma antingen den exakta adressen för posten eller det område inom vilket posten kan lokaliseras. Direkt organisation ger snabbast åtkomst till enskilda poster i en fil, men ansvaret för att skapa och underhålla en datauppsättning vilar på användaren. Direktorganisation används när det är nödvändigt att arbeta med filer som har en annan struktur än de som skapas av operativsystemet.
Åtkomstmetoder
I sek. 17.4 kommer att beskriva kringutrustning och hur man direkt programmerar driften av dessa enheter. Men i verkligheten är det ytterst sällsynt att behöva programmera på en så låg nivå. För att i stället organisera olika slags utbyten mellan minne och kringutrustning, samt skapa och underhålla datamängder för olika organisationer, används speciella systemprogram, som kallas åtkomstmetoder. Ett I/O-kommando som använder åtkomstmetoder är ett anrop till en uppsättning systemprogram som kallas I/O-övervakaren. Själva I/O-operationerna utförs redan direkt av I/O-övervakaren med hjälp av de rutiner som är associerade med den. I själva verket betyder detta att när man använder accessormetoder, finns det inget behov av att ta hand om de specifika detaljerna som är associerade med att utföra I/O-operationer, detta sköts av accessormetoderna själva.
Varje operativsystem tillhandahåller flera åtkomstmetoder. Valet av en viss metod beror på själva operativsystemet, på organisationen av datamängden som bearbetas och slutligen på den erforderliga buffertmetoden.

Ris. 17.5. (a) Enkel buffring fördröjer exekveringen av programmet tills bufferten är full, (b) Användningen av flera buffertar säkerställer att programexekveringen och dataöverföringen kombineras.
Buffertar. Buffertar är minnesområden som är utformade för att rymma information som matas in från en kringutrustning eller information som är förberedd för utmatning till en kringutrustning. I det vanligaste fallet ges buffertens adress tillsammans med inmatningsbegäran. I/O-övervakaren matar direkt in ett block från någon enhet i en buffert. Om vi vill producera output måste vi själva ta hand om det lämpliga innehållet i bufferten. När datan är klar skickas en utmatningsbegäran, försedd med buffertens adress; själva utmatningen utförs direkt av systemet.
På fig. 17.6a visar sekvensen av händelser som inträffar när en enda buffert periodiskt begärs för inmatning. Inmatningen begärs av användarprogrammet. Eftersom driften av användarprogrammet med största sannolikhet inte kan fortsätta till slutet av utbytet, avbryter handledaren temporärt dess exekvering till slutet av utbytet.
Utföra I/O-operationer även med de flesta snabba enheterär relativt långsam, under denna tid kan processorn vanligtvis utföra tusentals operationer. Användning av endast en buffert saktar alltså ner programmets exekvering avsevärt. Man ska dock inte tro att medan I/O pågår kan processorn inte utföra några andra operationer. Som vi kommer att se i sek. 17.4, System 360 och 370-datorer tillåter samtidig drift av processor och kringutrustning. I sådana fall talar man om att kombinera exekveringen av I/O-operationer med exekveringen av vanliga programkommandon.
Möjligheten till en sådan kombination kan framgångsrikt utnyttjas genom att göra utbyten, till exempel med två buffertar. Ett exempel på sådan användning visas i fig. 17.5.6. Vid sekventiell behandling organiserar handledaren inmatningen av information i den ordning som den finns i filen. Således kan systemet i själva verket "förutse" nästa förfrågningar, fylla bufferten även innan det tar emot en inmatningsorder. Faktum är att om användarprogrammet inte bearbetar data snabbare än att systemet kan fylla och tömma buffertarna, kan du använda flera buffertar samtidigt för att minimera förlusterna som uppstår på grund av behovet av att utföra I/O-operationer. Användningen av flera buffertar gör att du också kan öka den totala hastigheten på informationsutmatningen.
Men endast med sekventiell databehandling kan användningen av flera buffertar ge en tidsvinst. Om data behandlas i en godtycklig, slumpmässig sekvens, förlorar det vi har kallat systemets "framsyn" sin mening.
Varje operativsystem tillhandahåller flera åtkomstmetoder. I vilken utsträckning en programmerare behöver vara involverad i många buffertrelaterade frågor beror till stor del på vilken åtkomstmetod som används. Vissa åtkomstmetoder tillåter användare att inte bry sig om buffertar alls och gör allt nödvändigt arbete automatiskt. I andra fall kan bufferthantering helt överlåtas till användaren. Det finns också metoder som ger användaren ett val om att använda systemets tjänster för att hantera buffertar eller inte.
DOS-systemåtkomstmetoder. Alla åtkomstmetoder för skivoperativsystemet förutsätter halvautomatisk buffringskontroll. För att systemet ska fungera är det nödvändigt att reservera ett eller två buffertområden inom ditt program. Om arbete utförs med två buffertområden, utförs alla I/O-operationer vid arbete med sekventiella filer av systemet redan innan riktiga förfrågningar tas emot. Användaren kan beställa att data ska låsas vid utgång och låsas upp vid ingång. I DOS är följande sätt att organisera datamängder möjliga: sekventiell, index-sekventiell och direkt. De huvudsakliga åtkomstmetoderna för DOS-systemet är:
Serial Access Method (SAM)
Indexed Sequential Access Method (ISAM)
Direct Access Method (DAM)
Tabell 17.1 Vissa OS-systemåtkomstmetoder
|
namn |
Mnemonics |
|
|
Köad sekventiell åtkomstmetod |
Sekventiell organisation av data, metod för åtkomst med köer |
|
|
Grundläggande sekventiell åtkomstmetod |
Sekventiell organisation av data, grundläggande åtkomstmetod |
|
|
Kö Indexerad sekventiell åtkomstmetod |
Skapande och sekventiell bearbetning av index-sekventiella filer |
|
|
Grundläggande indexerad sekventiell åtkomstmetod |
Godtycklig bearbetning av indexsekventiella filer |
|
|
BasicPartitioned Access Method |
Skapande och bearbetning av biblioteksdatauppsättningar |
|
|
Grundläggande direktåtkomstmetod |
Filbehandling med direkt organisation |
|
|
Tillgångsmetod för telekommunikation |
Interaktion med fjärrterminaler |
Åtkomstmetoder för OS-system. OS-åtkomstmetoder delas in i två klasser: grundläggande åtkomstmetoder och åtkomstmetoder i kö. Köadkomstmetoder ger helautomatisk buffringskontroll. Systemet sköter självt underhållet av buffertområdena. Systemet utför blockering och avblockering av poster. Köåtkomstmetoder används vid bearbetning av sekventiella och indexsekventiella filer. Dessa metoder låter dig uppnå maximal bearbetningseffektivitet med ett minimum av krav på användarprogrammet.
Jämfört med köade metoder är grundläggande accessorer mycket mer primitiva. Men de låter dig uppnå större flexibilitet i arbetet med data. En del av buffringskontrollen är nu användarens ansvar, och frisläppandet av register är också användarens ansvar. Grundläggande accessorer används främst när man hanterar inkonsekvent bearbetning av datamängder. Listan över de vanligaste åtkomstmetoderna för OS-system ges i Tabell. 17.1.
I vår granskning berörde vi bara lite frågor relaterade till datastrukturer och de möjligheter som tillhandahålls av operativsystemet för att utföra I/O-operationer. Ändå är detta material tillräckligt för att starta en diskussion om användningen av åtkomstmetoder i I/O-programmering. I det följande kommer vi endast att vara intresserade av sekventiella åtkomstmetoder med köer av OS- och DOS-system. Även om principen att använda en sekventiell åtkomstmetod med köer är gemensam för de två systemen vi studerar, är de specifika detaljerna fortfarande ganska olika. Det är klokt att endast täcka material relaterat till I/O-programmering på just ditt system. Efter det kan du dock titta på ett annat avsnitt för att bekanta dig med liknande punkter i arbetet med de två systemen.
Vi noterar det faktum att i moderna avancerade informationssystem innebär maskinell bearbetning av information en sekventiell-parallell i tid lösning av beräkningsproblem. Detta är möjligt om det finns en viss organisation beräkningsprocessen. Den beräkningsuppgift som genereras av källan till beräkningsuppgifter (CTS) adresserar förfrågningar till datorsystemet allt eftersom lösningen behövs. Organiseringen av beräkningsprocessen involverar bestämning av sekvensen för att lösa problem och genomförandet av beräkningar. Lösningssekvensen sätts utifrån deras informationsförhållande, dvs. när resultatet av att lösa ett problem kan användas som indata för att lösa ett annat. Beslutsprocessen bestäms av den accepterade beräkningsalgoritmen. Beräkningsalgoritmer bör kombineras i ϲᴏᴏᴛʙᴇᴛϲᴛʙii med den nödvändiga tekniska sekvensen för att lösa problem till en beräkningsgraf för ett informationsbehandlingssystem. Därför kan man i ett datorsystem peka ut ett avsändningssystem (SD), som bestämmer organisationen av beräkningsprocessen, och en dator (kanske mer än en) som tillhandahåller informationsbehandling.
Det är värt att säga att varje beräkningsuppgift som kommer in i beräkningssystemet kan betraktas som en slags begäran om service. Sekvensen av beräkningsuppgifter i tid skapar en ström av förfrågningar. I ϲᴏᴏᴛʙᴇᴛϲᴛʙii med krav på organisation av beräkningsprocessen är det möjligt att omfördela inkommande uppgifter baserat på det accepterade schemaläggningsschemat. Därför bör ϲᴏᴏᴛʙᴇᴛϲᴛʙ-enheter och schemaläggningsenheter tillhandahållas i datorsystemets struktur, som säkerställer implementeringen av den optimala organisationen av beräkningsprocessen.
På fig. 4.3 presenterar ett generaliserat blockschema över datorsystemet. TEE genererar ett inputflöde av applikationer för deras lösning.
Med hjälp av dispatcher D1 implementeras motiveringen av den inkommande begäran och den placeras i O1 ... ON-kön, som implementeras på RAM-celler. Applikationer visas med koder och väntar på tjänstestart, beroende på informationsförhållandet mellan uppgifterna. Dispatcher D2 väljer en servicebegäran från köerna, dvs. överför beräkningsuppgiften som ska bearbetas av datorn. Underhåll utförs vanligtvis i ϲᴏᴏᴛʙᴇᴛϲᴛʙii med en accepterad plan för att organisera beräkningsprocessen. Processen att välja en applikation från en uppsättning kallas utskick. Vanligtvis väljs den applikation som har företrädesrätt till service. När ϶ᴛᴏm initieras ϲᴏᴏᴛʙᴇᴛϲᴛʙ, vilket implementerar beräkningsalgoritmen för att lösa problemet. Om det inte finns några förfrågningar i köerna, kopplar avsändaren D2 om datorprocessorerna till vänteläge. I det allmänna fallet implementeras en parallelltjänst i ett datorsystem på grund av närvaron av flera datorer (dator1 ... DATOR) Vi kan anta att serviceprocessen utförs i två steg. Först köas applikationer med hjälp av dispatcher D1, och i nästa steg betjänas de genom att välja applikationer från kön av dispatcher D2. Dispatchers D1 och D2 är implementerade i mjukvara och är kontrollprogram. Informationsprocesser i automatiserade system för organisationsledning implementeras med hjälp av datorer och andra tekniska medel. Under utvecklingen av datortekniken förbättras också formerna för dess användning. Det finns olika sätt att komma åt och kommunicera med datorer. Individuell och kollektiv tillgång till datorresurser beror på graden av deras koncentration och organisatoriska former av funktion. Centraliserade former för användning av datorverktyg som fanns före massanvändningen av datorer antog deras koncentration på ett ställe och organisationen av informations- och beräkningscentra (ICC) för individuellt och kollektivt bruk (IVCKP)
ITC:s och ICTSKP:s verksamhet kännetecknades av bearbetning av stora mängder information, användning av flera medelstora och stora datorer, kvalificerad personal för service av utrustning och utveckling av mjukvara. Den centraliserade användningen av datorer och andra tekniska hjälpmedel gjorde det möjligt att organisera deras tillförlitliga drift, systematiska laddning och underhåll av kvalifikationer. Centraliserad informationsbehandling tillsammans med ett antal positiva aspekter (hög grad av belastning och högpresterande användning av utrustning, kvalificerad personal från operatörer, programmerare, ingenjörer, datorsystemdesigners, etc.) hade ett antal negativa egenskaper, genererade främst av separation av slutanvändaren (ekonom, planerare, standardiserare, etc.) från den tekniska processen för informationsbearbetning.
Decentraliserade former för att använda datorresurser började ta form under andra hälften av 80-talet, då ekonomin fick möjlighet att gå över till massanvändning av persondatorer (PC) Decentralisering innebär placering av PC på platser där information genereras och konsumeras, där autonoma bearbetningspunkter skapas. Dessa inkluderar abonnentstationer (AP) och arbetsstationer.
Figur nr 4.3. Datorsystemets generaliserade struktur: IVZ - informationsdatorapplikation; D - avsändare; O - kö av förfrågningar om service
Behandlingen av ekonomisk information på en dator sker traditionellt centralt, och på mini- och mikrodatorer - på de platser där primär information uppstår, där automatiserade arbetsplatser är organiserade för specialister på en eller annan förvaltningstjänst (materialförsörjning och försäljningsavdelning, chef teknologavdelning, designavdelning, ekonomiavdelning, planeringsavdelning, etc.) En specialists automatiserade arbetsplats (AWS) inkluderar en persondator (PC) som fungerar autonomt eller i ett datornätverk, en uppsättning mjukvaruverktyg och informationsmatriser för att lösa funktionella uppgifter. Bearbetningen av ekonomisk information på en PC börjar när alla maskinens enheter är helt klara. Det är lämpligt att notera att operatören eller användaren, när han utför arbete på en PC, vägleds av en speciell instruktion för drift av hårdvara och mjukvara.
I början av arbetet laddas ett program och olika informationsmatriser (villkorligt konstanta, variabler, referens) in i maskinerna, var och en av dem bearbetas traditionellt först för att erhålla resultatindikatorer, och sedan kombineras matriserna för att erhålla dessa indikatorer.
Vid bearbetning av ekonomisk information på en dator utförs aritmetiska och logiska operationer. De aritmetiska operationerna för databehandling i en dator inkluderar alla typer av matematiska operationer som bestäms av programmet. Logiska operationer ger ϲᴏᴏᴛʙᴇᴛϲᴛʙ ordning av data i arrayer (primära, intermediära, konstanta, variabler) föremål för ytterligare aritmetisk bearbetning. En betydande plats i logiska operationer upptas av sådana typer av sorteringsarbete som beställning, distribution, urval, urval, fackförening. I samband med att lösa problem på en dator, i samband med ett maskinprogram, bildas resulterande datablad, som skrivs ut av en maskin. Utskrift av dokument kan åtföljas av en replikeringsprocedur, om det är extremt viktigt att ge ett dokument med resultatinformation till flera användare.
Observera att tekniken för elektronisk informationsbehandling— En människa-maskin-process för att utföra sammanlänkade operationer som sker i en föreskriven sekvens för att omvandla den initiala (primära) informationen till resultatet. Det är lämpligt att notera att en operation är ett komplex av tekniska åtgärder som utförs, som ett resultat av vilka information omvandlas. Det bör noteras att tekniska operationer är olika i komplexitet, syfte, implementeringsteknik, utförs på olika utrustning, av många utförare. Under förhållanden med elektronisk databehandling utförs operationer automatiskt på maskiner och enheter som läser data, utför operationer på givet program i automatiskt läge med deltagande av en person eller behålla funktionerna kontroll, analys och reglering för användaren.
Konstruktionen av den tekniska processen bestäms av följande faktorer: egenskaperna hos den information som bearbetas, dess volym, kraven på bearbetningens brådskande och noggrannhet, typerna, kvantiteten och egenskaperna hos de tekniska medel som används. Det är värt att notera att de utgör grunden för organisationen av teknik, vilket inkluderar upprättandet av en lista, sekvens och metoder för att utföra operationer, förfarandet för specialisternas arbete och automatiseringsverktyg, organisationen av arbetsplatser, inrättandet av tillfälliga föreskrifter för samspel m.m. Organisationen av den tekniska processen bör säkerställa dess ekonomi, komplexitet, driftsäkerhet och hög kvalitet på arbetet. Detta uppnås genom att använda ett systemtekniskt tillvägagångssätt för att designa teknik och lösa ekonomiska problem. Med ϶ᴛᴏm finns det ett komplext sammanhängande övervägande av alla faktorer, sätt, metoder för att bygga teknik, användningen av element av typifiering och standardisering, såväl som förenandet av tekniska processscheman.
Observera att tekniken för automatiserad informationsbehandling bygger på följande principer:
- integration av databehandling och möjligheten för användare att arbeta under driftförhållandena för automatiserade system för centraliserad lagring och kollektiv användning av data (databanker);
- distribuerad databehandling baserad på avancerade överföringssystem;
- rationell kombination av centraliserad och decentraliserad förvaltning och organisation av datorsystem;
- modellering och formaliserad beskrivning av data, procedurer för deras omvandling, funktioner och jobb för utförare;
- med hänsyn till de specifika egenskaperna hos objektet där maskininformationsbehandlingen är implementerad.
Organiseringen av i dess individuella stadier har ϲʙᴏ och funktioner, vilket ger upphov till allokering av out-of-machine och in-machine-teknik. off-machine-teknik(det kallas ofta pre-base) kombinerar operationerna för att samla in och spela in data, spela in data på maskinmedia med kontroll. Teknik i maskinen förknippas med organisationen av beräkningsprocessen i en dator, organisationen av datamatriser i minnet och deras strukturering, vilket ger anledning att kalla det också intrabase.
Huvudstadiet i informationsteknologiprocessen är förknippat med lösningen av funktionella problem på en dator. In-machine-teknik för att lösa problem på en dator implementerar traditionellt följande typiska processer för att konvertera ekonomisk information:
bildande av nya uppsättningar av information; beställning av informationsmatriser;
urval från en array av vissa delar av posten, sammanslagning och delning av arrayer;
göra ändringar i arrayen; utföra aritmetiska operationer på detaljer inom poster, inom matriser; över poster för flera arrayer.
Lösningen av varje enskild uppgift eller uppsättning uppgifter kräver följande operationer:
- inmatning av ett program för maskinlösningen av problemet och dess placering i datorns minne;
- inmatning av initiala data;
- logisk och aritmetisk kontroll av den inmatade informationen;
- korrigering av felaktiga uppgifter;
- arrangemang av inmatningsmatriser och sortering av den inmatade informationen;
- beräkningar enligt en given algoritm;
- erhållande av utdatamatriser av information;
- redigera utdataformulär;
- visning av information på skärmen och maskinmedia;
- utskrift.
Valet av en eller annan teknikvariant bestäms i första hand både av rymd-tidsegenskaperna för de uppgifter som löses, frekvensen, brådskan, kraven på kommunikationshastigheten mellan användaren och datorn och de tekniska resursernas kapacitet. - främst datorer.
Det finns följande sätt för interaktion mellan användaren och datorn: batch och interaktiv (begäran, dialog) Datorerna själva kan arbeta i följande lägen: enstaka och multiprogram, tidsdelning, realtid, telebearbetning. Med ϶ᴛᴏm är målet att möta användarnas behov i maximalt möjliga automatisering för att lösa olika problem.
Batch-läge var vanligast i praktiken av centraliserad lösning av ekonomiska problem, när en stor del var ockuperad av uppgifterna att rapportera om produktion och ekonomiska aktiviteter för ekonomiska objekt på olika nivåer av ledning. Organisationen av beräkningsprocessen i batchläge byggdes utan användaråtkomst till datorn. Dess funktioner begränsades till att förbereda initiala data för en uppsättning informationsrelaterade uppgifter och överföra dem till ett bearbetningscenter, där ett paket bildades som innehöll en uppgift för en dator för bearbetning, program, initiala, regulatoriska och referensdata. Paketet matades in i datorn och implementerades i automatiskt läge utan deltagande av användaren och operatören, vilket gjorde det möjligt att minimera exekveringstiden för en given uppsättning uppgifter. Med ϶ᴛᴏm kunde driften av datorn ske i ett enprograms- eller multiprogramläge, vilket är att föredra, eftersom maskinens huvudenheter kördes parallellt. Batchläge är för närvarande implementerat i förhållande till e-post.
interaktivt läge tillhandahåller direkt interaktion mellan användaren och informationsdatasystemet, kan ha karaktären av en begäran (vanligtvis reglerad) eller en dialog med datorn.
Begäran lägeär nödvändigt för användare att interagera med systemet genom ett betydande antal abonnentterminalenheter, inkl. avlägsen på avsevärt avstånd från bearbetningscentret. Det är detta behov som förorsakas av lösningen av driftsuppgifter av referens- och informationskaraktär, såsom till exempel uppgifterna att boka biljetter på transporter, rum i hotellkomplex, utfärda referensinformation m.m. Datorn implementerar i sådana fall ett kösystem, fungerar i ett tidsdelningsläge, med vilket flera oberoende abonnenter (användare) med hjälp av input-out-enheter har direkt och nästan samtidigt åtkomst till datorn i processen att lösa sina uppgifter . Detta läge gör det möjligt att ge varje användare tid att kommunicera med datorn på ett differentierat sätt på ett strikt etablerat sätt, och efter avslutad session, stänga av den.
Dialog läget öppnar möjligheten för användaren att direkt interagera med datorsystemet med en arbetshastighet som är acceptabel för honom, och realisera en upprepad cykel av att utfärda en uppgift, ta emot och analysera ett svar. Med ϶ᴛᴏm kan datorn själv initiera en dialog och informera användaren om sekvensen av steg (menypresentation) för att få önskat resultat.
Båda typerna av interaktivt läge (fråga, interaktivt) är baserade på driften av en dator i realtids- och telebearbetningslägen, vilket kommer att vara en vidareutveckling av tidsdelningsläget. Därför kommer de obligatoriska villkoren för att systemet ska fungera i dessa lägen, för det första, permanent lagring i datorlagringsenheter nödvändig information och program, och endast i minsta utsträckning mottagandet av initial information från abonnenter och, för det andra, tillgängligheten för abonnenter ϲᴏᴏᴛʙᴇᴛϲᴛʙ kommunikation innebär med en dator att komma åt den när som helst.
De övervägda tekniska processerna och arbetssätten för användare i "man-machine"-systemet kommer att vara särskilt tydliga under integrerad informationsbehandling, vilket är typiskt för modern automatiserad problemlösning i flernivåinformationssystem.
Utvecklingen av organisationsformer för datateknik bygger på en kombination av centraliserade och decentraliserade - blandade - former. En förutsättning för uppkomsten av en blandad form var skapandet av datornätverk baserade på olika kommunikationsmedel. Datornätverk involverar integrering av beräkningsverktyg, mjukvara och informationsresurser (databaser, kunskapsbaser) i ett system med hjälp av kommunikationskanaler. Nätverk kan täcka olika former av användning av datorer, och varje abonnent har möjlighet att få tillgång till inte bara deras datorresurser, utan även andra abonnenter, vilket skapar en rad fördelar i driften av datasystemet.
Nyligen pågår organisationen av användningen av datorteknik betydande förändringar i samband med övergången till skapandet av integrerade informationssystem. Integrerade informationssystem skapas med hänsyn till att de ska utföra konsekvent datahantering inom ett företag (organisation), samordna arbetet på enskilda avdelningar, automatisera informationsutbyte både inom enskilda användargrupper och mellan flera organisationer separerade från varandra av tiotals och hundratals kilometer.
Det bör noteras att lokala nätverk (LAN) utgör grunden för att bygga sådana system.Ett kännetecken för ett LAN kommer att göra det möjligt för användare att arbeta i en universell informationsmiljö med delade dataåtkomstfunktioner.
Under de senaste 3-4 åren har datoriseringen nått en ny nivå: datorsystem med olika konfigurationer baserade på persondatorer (PC) och kraftfullare maskiner skapas aktivt. De består av flera fristående datorer med gemensamma delade externa enheter (diskar, band) och enhetlig hantering, de möjliggör ett mer tillförlitligt skydd av datorresurser (enheter, databaser, program), ökar feltoleransen, säkerställer enkel uppgradering och ökar systemkapaciteten .
Mer och mer uppmärksamhet ägnas åt utvecklingen av inte bara lokala, utan också distribuerade nätverk, utan vilka det är otänkbart att lösa moderna problem med informationshantering.
Med tanke på beroendet av graden av centralisering av datorresurserna förändras användarens roll och hans funktioner. Med centraliserade formulär, när användare inte har direktkontakt med datorn, är dess roll att överföra de initiala uppgifterna för bearbetning, få resultat, identifiera och eliminera fel. Med direkt kommunikation mellan användaren och datorn utökas dess funktioner inom informationsteknologin. Det är värt att notera att han själv anger data, bildar en informationsbas, löser problem, får resultat och utvärderar deras kvalitet. Användaren öppnar verkliga möjligheter att lösa problem med alternativa alternativ, analysera och välja det lämpligaste alternativet med hjälp av systemet under specifika förhållanden. Alla ϶ᴛᴏ implementeras på en arbetsplats. Från användaren med ϶ᴛᴏm krävs kunskap om grunderna inom datavetenskap och datateknik.
I slutet av detta stycke noterar vi att beskrevs på högsta nivå ("top view"). En mer detaljerad övervägande av den ϶ᴛᴏ:e processen, studien av dess egenskaper hos olika tjänstemodeller (schemaläggning) kommer att vara innehållet i speciella discipliner.
PÅ datateknik det finns en tydlig skillnad mellan funktionerna sättning, bearbetning av visuell information och layout. Anledningen till att prepress-processen delas upp i tre steg är den olika karaktären hos text och grafisk information, samt ett helt oberoende steg av att kombinera text och grafisk information till en helhet, utfört under layoutprocessen.
Huvudstegen i tryckförtrycksprocesser visas i fig. 2.1.
En ordbehandlare är utformad för att skapa textmaterial med styckebrytningar och primära textformateringselement. Specialapplikationer används för att ställa in tabeller och formler.
Text som skrivs i ordbehandlare och sparas som källfiler för sättning kan vara av två typer.
Den första typen är själva textfilen, där information endast kodas om texttecken som har ett standardteckensnitt (oformaterad fil).
Den andra typen är en fil med formatering, som innehåller information inte bara om tecken, utan också om hur dessa tecken representeras, d.v.s. teckensnitt, storlekar, stilar, styckebrytningar.
I allmänhet bör datorskrivning tillhandahålla maskinskrivning, tabell- och formelmaterial. I enlighet med huvudtyperna av skrivning används lämpliga mjukvaruverktyg, och skrivning utförs i en ordbehandlare, till exempel i MS Word, ett av de mest använda textprogrammen. För en uppsättning tabeller och slutsatser kan Word eller Excel användas, och för en uppsättning formler används professionella X Match-formeluppsättningsprogram och andra. Microsoft Word dominerar idag ordbehandlarmarknaden främst på grund av dess utbredning. Det finns dock flera snabbare, mer pålitliga och rikare ordbehandlare än Word.
Tekniken för bearbetning av text och grafisk information innefattar följande processer: maskinskrivning, bildbehandling, layout, korrekturutskrift, screening, utmatning av den formade remsan på fotografiskt material, fotokemisk bearbetning. Dessa operationer utförs på basis av det inlämnade originalet.
Processen att bearbeta text och grafisk information består av tre steg:
Ange information;
Databehandling;
Informationsutmatning.
De huvudsakliga metoderna och tekniska medel som används vid inmatning och bearbetning av information visas i fig. 2.2.
Maskinskrivningsprocessen består i att konvertera textinformation från formen av ett handskrivet eller annat original till formen av elektroniska koder lagrade på ett magnetiskt lagringsmedium. Korrektheten av den maskinskrivna textinformationen kontrolleras under korrekturläsning. Under korrekturläsningen kontrolleras förekomsten av grammatiska fel, teckensnittshöjdpunkter, korrektheten av uppsättningen tabeller och formler.
Hela komplexet av tekniska operationer för bearbetning av text- och illustrativ information visas i fig. 2.3.
Vid polygrafisk reproduktion går en del av originalets figurativa information förlorad. Detta beror på det faktum att intervallet för optiska densiteter (skillnaden mellan den maximala och minsta optiska densiteten i bilden) för det utskrivna trycket är mindre än originalets. För den mest exakta återgivningen av kontrasten i bilddetaljer är det nödvändigt att ändra graderingsöverföringskurvan, med hänsyn till originalets informationsinnehåll. Tillsammans med detta introducerar formen och tryckprocesserna för tryckproduktion ytterligare förvrängningar i överföringen av graderingar av den reproducerade bilden. För att kompensera för förlusten av bildinformation vid kopiering av blanketter och utskrift, införs så kallade predistortioner i graderingsöverföringskurvan, vilket gör det möjligt att undvika en minskning av kvaliteten på utskriftsreproduktionen. Moderna grafiska stationer för bildinformationsbehandling är utrustade med en uppsättning applikationsprogram för bildbehandling LinoColor och Photoshop. En av funktionerna (subrutinerna) hos ett sådant program för att bearbeta bildinformation är funktionen för graderingskorrigering.
När du anropar i programmen LinoColor och Photoshop visas en graf över beroendet mellan ljusstyrkanivåerna (optisk densitet) för signalen vid systemets ingång och utgång på skärmen. Med hjälp av "musen" är det möjligt att ändra formen på graderingskurvan, och därmed kan systemoperatören ändra tonöverföringsgradienterna i bildens informationszoner: i högdagrar, halvtoner, skuggor. Graderingstransformationer kan utföras både för alla färgkomponenter som helhet och för varje enskild tryckfärg (gul, magenta, cyan, svart). Programmet LinoColor ger möjlighet att ändra (begränsa) det dynamiska området för optiska densiteter, och Photoshop-programmet ger information om frekvensen av förekomst av bildelement med en given ljusstyrka. I det här fallet visas ett histogram av ljusstyrkefördelningen över det analyserade bildområdet på skärmen.
För att få en högkvalitativ tryckt reproduktion är det nödvändigt att uppnå så nära möjliga matchning mellan originalets och tryckets färgnyanser. Det bör beaktas att originalets färgomfång är mycket bredare än det tryckta trycket. Förekomsten av en oöverensstämmelse i färgomfång, såväl som vissa signalförvrängningar som uppstår när man går in i systemet, dikterar behovet av en färgkorrigeringsoperation, med hänsyn till parametrarna för det reproducerade originalet och utskriftsprocessen. Varje färg kan beskrivas med minst tre parametrar (koordinater). Koordinatsystem bildar olika färgrymder. De mest kända färgrymden är RGB, CMYK och LCH (CIELab). RGB-färgrymden används i skannrar och TV-system, inklusive datorskärmar. R,G,B koordinaterär proportionella mot rött, grönt respektive blått ljus. CMYK-färgrymden används vid utskrift, koordinatvärdena motsvarar mängden cyan, magenta, gult och svart bläck på trycket. Men när man använder CMYK-systemet finns det osäkerheter förknippade med att tryckfärger skiljer sig i färgton. För att förena färgmätningar har ett standardiserat LCH-system införts, vars användning ska säkerställa att färgerna som uppfattas av skannern matchar färgerna på monitorn och tryckfärgerna.
Det tryckta originalet innehåller som regel en rasterstruktur, moirérosetter. Vid inmatning spelas sådana högfrekventa element tillsammans med huvudbilden, vilket minskar återgivningskvaliteten. Dessutom, när man skannar en rasterstruktur, finns det en möjlighet till diskretisering av moiré. I ett betydande antal fall finns det ett behov av att skärpa objekt för att framhäva konturerna av bilddetaljer. För att förbättra kvaliteten på återgivningen utförs skärpakorrigering. Om det är nödvändigt att bli av med små detaljer (till exempel rasterstruktur, damm), minskar skärpan. För att utföra dessa operationer utförs skärpeminskning (avastrering, suddighet). Tvärtom, för att betona konturerna, utförs skärpning, till exempel med hjälp av oskarp maskeringsmetoden. LinoColor och Photoshop har speciella funktioner som utför de nödvändiga operationerna. Genom att ställa in funktionsparametrarna kan du uppnå graden av anslag (djup) av skärpning eller skärpning. Photoshop är utrustad med speciella subrutiner - filter, som ger ett brett utbud av alternativ för skärpakorrigering. Ett antal skärpekorrigeringsoperationer brukar kallas teknisk retuschering.
Original som är föremål för tryckreproduktion är ofta inte fria från mekanisk skada: Repor, böjningar, damm etc. kommer in i dokumentplåten innan den placeras på den. För att eliminera sådana defekter utförs teknisk retuschering.
Den moderna processen för bildinformationsbehandling kräver skapandet av kombinerade bilder, som inkluderar objekt, detaljer som ursprungligen ligger på olika original. Bildredigering inkluderar operationerna att välja det valda objektet (intressant område) på originaloriginalet, lagra den valda zonen i den tillfälliga lagringsbufferten och överföra den till den slutliga bilden.
Om det är nödvändigt att utföra en korrigerande operation inte på hela bilden, utan bara på en del av den, väljs också den intressanta zonen preliminärt, varefter de nödvändiga omvandlingarna (konstnärlig retuschering) utförs.
I LinoColor-programmet är det tillrådligt att utföra enbart gradering, färg och skärpa. Photoshop är mer avsett för redigering, applicering av geometriska ornament (rektanglar, ellipser, linjer) och textinskriptioner på bilden. Närvaron i Photoshop av ett stort antal inbyggda specialrutiner, den så kallade. filter, ger ytterligare möjligheter för att utföra konstnärlig retuschering: överlagring av den förberedda bilden tredimensionellt objekt, ändra belysningen på bilden osv.
Att kombinera text- och visuell information på en enda sida i publikationen utförs under layouten. Efter att ha angett och bearbetat alla nödvändiga texter och bilder, beskriver operatören (eller konstnärlig och teknisk redaktör) layouten för den framtida sidan. Samtidigt, med hjälp av QuarkXpress eller PageMaker datorlayoutprogram, anges det utrymme som tilldelats för framtida kolumner med text och illustrationer på remsan. Särskilda programkommandon upprättar en överensstämmelse mellan filer som innehåller text eller grafisk information och deras framtida platser. Valet av nödvändig typsnitt, stil och teckenstorlek görs, kolumnnummer, sidfötter, fotnoter, mellanspalter, illustrationsramar och bildtexter placeras under figurerna.
Det finns följande typer av layout: enkel, blandad och komplex. Enkel layout är layouten för textpublikationer på små sidor. Blandad layout ger möjlighet att inkludera poetisk text, dramatiska textverk med tabeller, formler etc. Komplex layout är layouten av flersidiga publikationer med ett betydande antal illustrationer, informations- och referensapparater etc.
Layout är inte bara en monteringsprocess, utan har också en betydande inverkan på skapandet av en viss form av publicering. Därför betraktas designstilen, tillsammans med text och illustrationer, som den första komponenten i layouten.
Det speciella med layout med hjälp av ett publiceringsprogram (paket) är att det fungerar som en slags mottagare för text- och grafikfiler förberedda i andra applikationer, och har mjukvaruverktyg och ett gränssnitt för att placera dem inom gränserna för remsor och kolumner . De viktigaste kraven för russifierade verstalprogram är tillgången på importverktyg och ordböcker för överföring av ryska texter.
De vanligaste för layout och typsättning av publikationer är publiceringsprogrammen PageMaker och QuarkXPress. Layouten av sidorna i den första av dem är baserad på direkt placering av text och grafik inom gränserna för en typrad eller kolumn. Det speciella med det andra programmet är att texten eller illustrationen laddas först in i en grafisk ram (ram), som sedan placeras i arbetsområdet, som simulerar en kartong.
När du startar layout är det nödvändigt att lösa den första frågan, om ett helt nytt dokument skapas där sidparametrar (band) måste ställas in, eller färdiga sidmallar kan användas, där alla layoutparametrar redan är definierade . Den tekniska originaldokumentationen (beställningskort, layoutlayout) måste innehålla nödvändiga data för att markera textremsan.
Den grundläggande strukturen för vilken sida som helst bildas på skärmen med hjälp av ett modulärt rutnät som består av fältkanter, såväl som vertikala och horisontella guider. Stigningen för det modulära nätet av horisontella linjer sätts lika med den ledande. Modulärt rutnät säkerställer enhetlighet för jämna och udda sidor, arrangemang och storlek på kolumner med text, och så vidare. Alla konstruktionslinjer visas endast i layoutläge.
I layoutstadiet utförs den slutliga redigeringen av texten med hjälp av en materialredigerare anpassad till layoutens behov. Att byta till redigeringsläge och återgå till layoutläge är nästan omedelbart tack vare den förenklade visningen av text och grafik i Material Editor.
För att kontrollera det korrekta arrangemanget av text och illustrationer på remsan, samt för ytterligare korrekturläsning, är det lämpligt att utföra ett provtryck på laserskrivare. Men eftersom bilden är i svartvitt är det inte möjligt att bedöma kvaliteten på färgbildbehandlingen utifrån denna utskrift. Samtidigt innehåller ett sådant provtryck tillräckligt med information om remsans struktur, huvudproportionerna för sektionerna av remsorna och illustrationerna och storleken på bilddetaljer. I vissa fall lämpar sig ett provutskrift som erhållits på en svartvit laserskrivare att signera för utskrift som en kontrollkopia.
I det sista steget av element-för-element-behandling av signalen utförs rastreringsoperationen. Rasteriseringsoperationen involverar omvandlingen av en elektronisk halvtons digital bild till en mikrolinjebild, bestående av separata rasterelement. Ett rasterelement är en kvadratisk cell med en rasterpunkt i mitten. Storleken på rasterelementet T [mm] bestäms av rasterlineaturen L [lin / cm], och kan beräknas som T = 10/L. Värdet på storleken på rasterelementet är konstant på varje färgseparationsfotoform. Storleken på halvtonspunkten beror på bildens överförda optiska densitet. Värdet på punktstorleksvärdet bestäms av dess relativa area S. Värdet på S varierar från 0 % (ljusa områden) till 100 % (mörka områden).
Rasterisering av bilder utförs med hjälp av en speciell rasterprocessor (RIP), som omvandlar en halvtonsbild som beskrivs i PostScript-språket till en uppsättning rasterpunkter. Rasterpunkten är bildad av delelement, som registreras på det fotografiska materialet med en laserstråle. Formen och storleken på en rasterpunkt beräknas av RIPom med hjälp av speciella tabeller (rasterbilder). På fig. Figur 2.4 visar ett rasterelement genererat av RIP. Moderna ASPTS är utrustade med typiska graderingsegenskaper och tillåter operatören att göra ändringar i vissa områden av graderingskarakteristiken (i högdagrar, mellantoner och skuggor).
I det sista skedet överförs digital information som kännetecknar den upplagda skärmade remsan till en fotoutmatningsanordning, i vilken en uppsättning färgseparerade fotoformer spelas in sekventiellt. Färgseparationsbilder bildas på fotografisk film, som är förinstallerad i en fotoutmatningsenhet. Exponeringen utförs av en laserljuskälla. Efter exponering kommer den fotografiska filmen med den latenta bilden av färgseparationsbanden in i den mottagande kassetten. Efter fullständig exponering av uppsättningen färgseparationsremsor tas mottagningskassetten bort från fotoutmatningsenheten och installeras i bearbetningsmaskinen.
Fotokemisk bearbetning utförs i bearbetningsmaskiner. Grundprincipen för att bygga bearbetningsmaskiner (processorer) för filmbearbetning är principen att kombinera en komplett teknisk cykel i en maskin. I processorn framkallas filmen sekventiellt, fixeras, tvättas med vatten och torkas. Den utvecklande processorn kan arbeta i linje med FVU eller separat. I utvecklingsprocessen kontrolleras huvudparametrarna för processordriften, såväl som filmens kvalitet.
Efter exponering i en kopiator bildas en latent bild av mönstret av den framtida tryckplåten på offsetplattans yta. Bearbetningen av offsetplåtar i speciella processorer gör det möjligt att säkerställa bildandet av hydrofobt tryck och hydrofila tomma element på tryckplåten. Ytterligare tryckt formulär tvättas med vatten, torkas och täcks slutligen med ett skyddande lager. Processorer har hög nivå automatisering och styrs av speciella program.